在第六代无线系统(6G)的技术浪潮中,数字孪生边缘网络(Digital Twin Edge Network, DITEN)作为一项关键范式,正以其强大的数据建模与实时优化能力,为智能应用的未来铺平道路。微云全息(NASDAQ:HOLO)最新研发的“数字孪生边缘网络中的节能联邦学习与迁移技术”通过创新性地解决联邦学习(FL)任务的数字孪生关联与历史数据分配问题,显著提升了系统的能源效率与数据效用。这一技术的发布,不仅标志着微云全息在6G技术领域的重大突破,也为边缘计算、隐私保护与可持续发展提供了全新的解决方案。
数字孪生(Digital Twin)技术通过为物理实体创建虚拟镜像,实时映射其状态与行为,已成为工业4.0、物联网(IoT)以及智能城市等领域的核心技术。在6G网络中,数字孪生边缘网络(DITEN)将这一概念进一步扩展到边缘计算环境中,通过在边缘节点上构建高精度的数字模型,实现对复杂系统(如智能交通、工业自动化、医疗设备)的实时监控与优化。然而,传统的数字孪生技术在长期维护过程中面临两大挑战:一是高昂的能源成本,二是涉及用户隐私的数据处理需求。
联邦学习(Federated Learning, FL)作为一种分布式机器学习方法,允许在不共享原始数据的情况下,通过多设备协作训练模型,天然适合需要隐私保护的场景。然而,在DITEN中引入FL任务时,数据分配、模型训练与数字孪生同步之间的复杂交互,往往导致资源利用效率低下与能源消耗激增。微云全息的研发团队敏锐地捕捉到这一问题,提出了“数字孪生关联与历史数据分配”的优化框架,旨在通过联合优化数据效用与能源成本,为6G网络中的智能应用提供高效、可持续的解决方案。
微云全息的这项技术围绕DITEN中联邦学习任务的数字孪生关联与历史数据分配问题展开,核心目标是实现数据效用与能源成本的协同优化。该技术需要解决以下几个关键问题:
首先,如何准确预测FL任务的训练精度。这需要一个能够量化数据贡献与模型性能之间关系的数学模型。其次,如何在满足隐私约束的前提下,高效分配历史数据以支持FL任务的训练。最后,如何在长期DITEN维护中平衡FL模型训练、数据同步以及数字孪生迁移的能源成本。这些问题相互交织,构成了一个复杂的多目标优化难题。
为此,微云全息研发团队提出了一种创新的闭式函数,用于预测FL任务的训练精度,称之为“数据效用”。该函数通过分析历史数据的特征分布与模型参数的收敛特性,能够准确评估不同数据分配策略对模型性能的影响。与此同时,团队对FL方法的收敛性进行了深入分析,确保优化算法能够在有限的计算资源下快速找到全局最优解。
在能源成本方面,微云全息(NASDAQ:HOLO)的研究涵盖了FL模型训练、数据同步以及数字孪生迁移的多个环节。FL模型训练需要边缘设备执行本地计算并定期与中心服务器同步参数,这会产生显著的计算与通信开销。数据同步涉及边缘节点与数字孪生模型之间的实时数据交互,而数字孪生迁移则需要在不同边缘节点间动态调整模型位置,以适应网络拓扑的变化。优化框架通过联合建模这些过程,实现了能源效率的最大化。
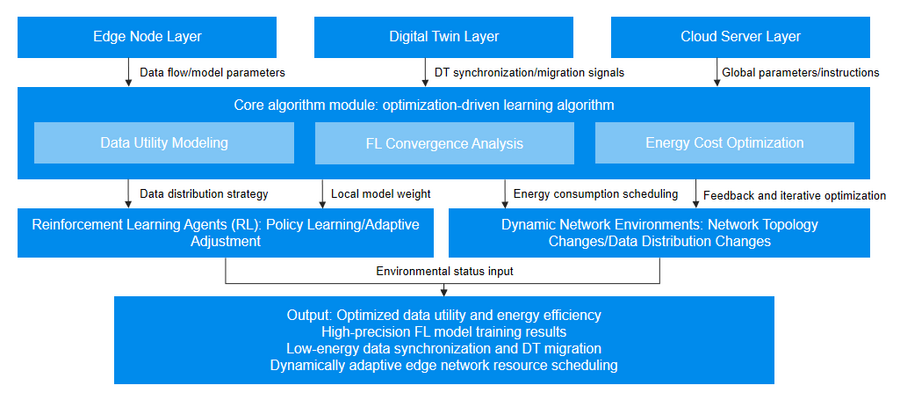
微云全息的节能联邦学习与迁移技术依赖于一种新颖的优化驱动学习算法,其设计理念是将复杂的多目标优化问题分解为可管理的子问题,并通过迭代求解逐步逼近全局最优解。
数据效用是整个优化框架的核心。团队设计了一个闭式函数,用于量化历史数据对FL任务训练精度的贡献。该函数基于信息论与统计学习理论,综合考虑了数据的多样性、分布特性以及与模型目标的相关性。数据效用函数可以表示为:
[ U(D) = f(D_{\text{div}}, D_{\text{rel}}, \theta) ]
其中,( D_{\text{div}} )表示数据的多样性,衡量数据样本的异质性;( D_{\text{rel}} )表示数据与任务目标的相关性;( \theta )为模型参数。函数 ( f )通过分析历史数据的统计特性,预测其对模型收敛速度与精度的贡献。这一闭式表达不仅降低了计算复杂度,还为后续优化提供了理论依据。
为了确保算法的有效性,微云全息对所提出的FL方法进行了全面的收敛性分析。传统的FL算法在异构数据场景下往往面临收敛速度慢或不稳定的问题。微云全息通过引入数据效用函数,优化了本地模型更新的权重分配策略,从而加速全局模型的收敛。算法采用了一种加权聚合机制:
[ \theta_{t+1} = \sum_{i=1}^N w_i \theta_i^t ]
其中,( \theta_i^t )为第 ( i )个边缘设备在第 ( t )轮的本地模型参数,( w_i )为基于数据效用的动态权重。这种加权策略能够优先利用高质量数据,显著提升模型的训练效率。
在能源成本优化方面,微云全息的算法综合考虑了以下三个方面的开销:
FL模型训练:边缘设备执行本地模型更新时需要消耗计算资源。微云全息通过动态调整训练频率与批量大小,降低了计算能耗。
数据同步:边缘节点与数字孪生模型之间的数据交互需要通信资源。微云全息设计了一种自适应的同步协议,根据网络状况与数据重要性动态调整同步频率。
数字孪生迁移:当网络拓扑发生变化时,数字孪生模型需要在不同边缘节点间迁移。微云全息提出了一种基于预测的迁移策略,通过分析历史迁移模式,提前规划最优迁移路径,从而减少通信与计算开销。
通过联合优化这三个方面,微云全息的算法能够在保证FL任务性能的同时,将能源成本降至最低。
再优化驱动的学习算法方面,核心算法采用了一种基于梯度下降的迭代优化框架,将数据效用与能源成本的优化目标融入一个统一的损失函数:
[ L = \alpha (1 - U(D)) + \beta E_{\text{total}} ]
其中,( U(D) )为数据效用,( E_{\text{total}} )为总能源成本,( \alpha )和( \beta )为权重系数,用于平衡两个目标。算法通过交替优化数据分配策略与能源调度方案,逐步逼近全局最优解。
在实现过程中,微云全息(NASDAQ:HOLO)引入了强化学习(Reinforcement Learning, RL)技术,进一步增强算法的适应性。RL代理通过与DITEN环境的交互,学习最优的数据分配与资源调度策略。这种方法尤其适合动态变化的6G网络环境,能够实时应对网络拓扑、数据分布以及用户需求的变化。
微云全息的节能联邦学习与迁移技术在多个方面展现了显著优势。首先,通过数据效用函数的引入,算法能够精确评估数据对模型性能的贡献,从而优化数据分配策略。其次,基于收敛性分析的加权聚合机制显著提升了FL任务的训练效率。最后,联合优化的能源管理方案有效降低了长期DITEN维护的能源成本。
在性能评估中,微云全息团队通过数值实验对算法进行了全面验证。实验设置包括不同规模的边缘网络、多种数据分布模式以及动态网络拓扑。结果显示,微云全息的算法在数据效用与能源效率方面均优于传统方法。例如,与基于均匀数据分配的FL算法相比,微云全息的算法将模型训练精度提高了约15%,同时将能源消耗降低了约20%。与传统的数字孪生迁移策略相比,微云全息的预测性迁移方案将迁移延迟降低了约30%。
尽管微云全息的节能联邦学习与迁移技术已取得显著成果,但仍有进一步优化的空间。例如,未来的研究可以探索更复杂的多任务FL场景,解决不同任务之间的资源竞争问题。此外,结合量子计算或神经网络架构搜索(NAS)技术,可能进一步提升算法的性能与适应性。此外,微云全息计划在未来几年内将该技术推广至更多实际应用场景,并与行业伙伴合作,开发基于DITEN的标准化解决方案。同时,微云全息还将继续优化算法的计算效率,以适应资源受限的边缘设备,推动6G网络的可持续发展。
微云全息(NASDAQ:HOLO)的“数字孪生边缘网络中的节能联邦学习与迁移技术”通过创新性地解决数据效用与能源成本的联合优化问题,为6G时代的智能应用提供了高效、可持续的解决方案。这一技术的核心在于数据效用建模、收敛性分析以及优化驱动的学习算法,展现了微云全息在人工智能与通信技术融合领域的领先实力。随着6G网络的逐步部署,这项技术有望在智能交通、工业自动化、医疗等领域发挥重要作用,为构建更加智能、绿色与隐私安全的未来奠定基础。















