
芯东西(公众号:aichip001)
作者 | GTIC峰会
芯东西8月27日报道,今日,GTIC 2022全球AI芯片峰会在深圳市南山区圆满落幕。会上,2022「中国AI芯片企业50强」榜单正式揭晓。
 ▲智一科技联合创始人、总编辑张国仁揭晓榜单
▲智一科技联合创始人、总编辑张国仁揭晓榜单

这场高规格产业会议,由芯东西与智东西公开课联合主办,以“不负芯光 智算未来”为主题,汇集了来自AI芯片领域的产学研投专家及创业先锋代表,展示智能计算底层创新与落地的最新光景。
两天内,32位嘉宾通过主题演讲和巅峰对话,分享了干货满载、深入浅出的行业见解。峰会全场座无虚席,全网直播人数累计高达220万+人次。作为智一科技产业对接平台GTIC落地深圳的首场产业峰会,GTIC 2022全球AI芯片峰会得到了深圳产业人士的广泛好评。
昨日,我们整理了AI芯片高峰论坛和云端AI芯片专题论坛的核心看点。(AI芯片峰会燃爆深圳南山!17位大咖演讲万字精华来了)
今天,精彩继续!15位大牛分别出席边缘端AI芯片专题论坛、存算一体芯片专题论坛、新型计算技术专题论坛,畅谈AI芯片创新路径,以及在加速落地商用过程中积累的心得。
一、南科大余浩:“种草”低碳AI芯片,高精度与低功耗并存
南方科技大学深港微电子学院创院副院长余浩教授在现场“种草”了低碳AI芯片。
我们向往着让机器来做计算,帮助我们“躺平”,但就目前的算力中心而言,其在功耗和效率上都需要付出很大代价,如电力、能源的消耗。因此,在数字经济、可持续经济的背景下,我们需要一块高能效的低碳芯片。
 ▲南方科技大学深港微电子学院创院副院长余浩教授
▲南方科技大学深港微电子学院创院副院长余浩教授
现有的有效解决途径包括并行的GPU、脉动的TPU,不过这些解法或多或少仍存在功耗高、能效低的问题。那么,如何在保证精度、降低功耗的情况下训练出多精度、多复杂度模型并实现高能效的硬件计算?
余浩教授团队的做法是通过网络架构自动搜索设计,对网络进行逐层优化,得到高能效的混合精度神经网络;并在硬件层面,让每个数据单元都支持多精度并行处理,同时每个并行的多精度阵列又可以进行数据复用,就可以高能效地运行多复杂度的网络模型。
南方科技大学团队已经研发了4款AI芯片,其中,在平均能效情况下,X-Edge芯片达到200TOPS/W,超越人脑的10TOPS/W。
基于上述研发理念,X-Edge芯片可以应用于搭建低碳边缘算力平台、机器人平台、移动巡检平台、元宇宙平台等。
二、软硬件协同设计,应对AI落地碎片化难题
相对云端AI芯片,边缘侧与端侧的AI芯片企业面临着更为多元的应用场景,不止要通过优化底层技术,还必须抓住时间窗口,加速实现芯片及相应解决方案的规模化落地。
在上午举行的边缘端AI芯片专题论坛期间,来自时擎科技、爱芯元智、Imagination、齐感科技、英诺达、嘉楠科技的行业大牛,分享了他们观察到的下游市场需求之变,以及应对这些变化的产品创新、落地打法与实战经验。
1、时擎科技仇健乐:分布式存储与计算,应对端侧AI落地碎片化挑战
在AIoT时代,AI应用越来越多地以“云边端协同”形式出现。与云端AI芯片相比,端侧AI芯片需要满足一些特定需求,比如:算力能支持本地预处理或简单决策即可,对功耗和成本更敏感,传感器接口和应用市场碎片化等。
面向这样的市场特点,端侧智能芯片公司时擎科技选择采用DSA(领域专用架构)芯片设计方案,时擎采用神经网络数据压缩引擎,支持自主研发的基于RISC-V架构的端侧DSA智能处理器。
据时擎科技研发副总裁仇健乐分享,该处理器可进行分布式存储和计算,适应AI算法快速演进,保持高计算效率,目前已能在128GOPS-2TOPS算力范围内实现较强伸缩性。
 ▲时擎科技研发副总裁仇健乐
▲时擎科技研发副总裁仇健乐
当进入客户应用场景进行部署,设计好的AI端侧芯片又面临一大新的挑战——部署模型多为小型化网络模型,数据量化难度大。
为此,时擎通过TimesFlow平台提供多种量化方法,包括INT8/INT16的对称/非对称量化选项,从而降低量化过程中的精度损失。时擎还配备一键部署功能、丰富算子库、多种预处理方法,以优化客户的应用部署体验。
2、爱芯元智刘建伟:两大核心技术,加速端侧AI芯片落地
近10年AI技术发展迅猛,随着算力越来越大,市场空间暴涨,端侧和边缘侧的AI芯片也迎来发展机遇。在端侧、边缘侧对智能要求越多,需要的算法也就越多,同时,AI的应用也对感知和计算提出了更高的需求。
爱芯元智联合创始人、副总裁刘建伟说:“爱芯元智在AI芯片领域对感知和计算的探索,已经成功量产两代四颗芯片,并布局于消费电子、智慧城市领域。”
 ▲爱芯元智联合创始人、副总裁刘建伟
▲爱芯元智联合创始人、副总裁刘建伟
爱芯元智将感知和计算作为两大基础技术进行研发,其中,AI-ISP技术将AI与ISP(图像信号处理)相结合,选取传统ISP中的模块进行增强。混合精度NPU提供基础算力,可以实现模块间并行计算。
此外,爱芯元智提供的不仅是AI芯片,而是面向场景的解决方案,在设计整个芯片时,会帮助客户从芯片、应用到算法进行协同设计。
3、Imagination郑魁:CPU+GPU+AI异构计算,满足边缘智能多样化需求
随着人工智能市场快速增长,PC、智能手机、安全、 等市场都需要不同算力,为此,IP解决方案商Imagination最新推出了覆盖AI、GPU和CPU等IP的异构计算架构。
Imagination中国区⼈⼯智能及 产品市场副总郑魁谈道,作为一家IP设计公司,PPA(性能、功耗、面积)是产品一直强调的要素。同时面向手机、自动驾驶等各个领域的算力需求多样化,对硬件计算架构乃至软件栈有更高的需求。异构计算是未来的发展方向,对此,Imagination已在IP层面将所有计算异构能力整合,提供具备灵活性、标准化、开放性的解决方案。
 ▲Imagination中国区⼈⼯智能及
产品市场副总郑魁
▲Imagination中国区⼈⼯智能及
产品市场副总郑魁
在AI方面,Imagination推出了NNA(神经网络加速器)等IP产品,已落地自动驾驶、consumer等多个领域;在CPU方面,最新推出基于RISC-V的RTXM-2200,是其首款实时嵌入式的高度可扩展的实时、确定性、32位嵌入式CPU;在GPU方面,基于PowerVR开拓性架构除了出色的PPA,还具备强大的算力可拓展性。Power VR架构走过30载,如今高算力IMG GPU已拓展至桌面、车载、高性能计算等多个新市场。
4、齐感科技刁勇:芯片+解决方案,助不同AI场景的应用快速落地
齐感科技市场副总裁刁勇谈道,AI产业市场正在高速发展,目前较典型的AI应用包括语音识别、自然语言处理、视觉应用,其中视觉应用是成长最快速的。
 ▲齐感科技市场副总裁刁勇
▲齐感科技市场副总裁刁勇
智慧家居、智慧零售、智慧农牧、机器人、智慧教育等落地场景,对AI视觉芯片有非常强的需求。对于AI视觉芯片公司来说,仅利用自己的经验来应对不同业务需求,可能会面临很多的挑战。对此,齐感科技以AI SoC芯片为核心,推出全套解决方案,来帮助客户在设计相关产品时快速落地。
目前,齐感科技已经推出两代芯片平台QG21、QG31,包含8颗芯片,并在此基础上布局了智能网络摄像机、低功耗视觉应用,智能门锁、AI智能分析盒子、智能云台、翻译机等解决方案。
此外,很多不带AI的摄像头已经部署应用,但它们可能有实际上有升级、增加AI加速能力的需求,齐感科技的AI智能分析解决方案则给这些产品提供了升级路径。
5、英诺达李曦:大型AI芯片验证平台,应对芯片设计上云需求
算力成为半导体行业的新增长点,人们在追求更先进的制程工艺时,IC设计成本随之快速上升,芯片设计软件EDA上云成为新趋势。
英诺达市场与销售总监李曦谈道,IC设计上云面临数据安全、商务模式、技术支持等多重挑战。EDA龙头Cadence推出的Palladium硬件仿真加速器是业界较通用的硬件仿真器,支持百亿门级的SoC全芯片验证;但它价格昂贵,安装及维护要求高,中小公司往往难以负担。
 ▲英诺达市场与销售总监李曦
▲英诺达市场与销售总监李曦
为此,英诺达推出国内首个基于且由Cadence独家授权的Palladium的异构云平台,在国内搭建异构机房以保证安全可控和数据快速传输,并将费用降低到中小公司可负担的范围,目前已形成按需使用、按时收费的商业模式。
同时,该平台也会提供机器故障诊断及维修、客户配置初始调试、验证环境搭建等技术支持。在疫情期间,英诺达的云服务优势明显,客户的机器利用率保持在80%以上,不仅可以让用户持续推进研发进度,还可以让用户把更多精力放在体现其核心竞争力的芯片设计上。
6、嘉楠科技汤炜伟:拥抱软硬件开源生态,算法平台和仓库帮助轻松部署
“AI应用的发展逐渐变得场景化、设备化、多样化。”嘉楠科技副总裁汤炜伟说。AI先起于云端,随着技术不断成熟、AI算法模型裁剪量化,AI芯片性能和性价比不断提升,边缘的AI算力变得更加普及。
 ▲嘉楠科技副总裁汤炜伟
▲嘉楠科技副总裁汤炜伟
边缘AI计算设备形态多元化,这导致未来该领域的开发并不只在大公司,更多中小公司、个人开发者都会参与进来。不过在开发过程中,开发者往往直面很多门槛,比如选择芯片平台、买不到芯片硬件、获取开发资料和获得支持等。在他看来,降低门槛最好的途径就是开源。
因此,嘉楠科技采用RISC-V的通用处理器核架构,多代自研KPU架构,实现全流程的研发自主研发,能够对开源开放、快速迭代和客户支持有更好支撑。近两三年嘉楠科技已经实现超200万颗RISC-V AI芯片出货。
另外,新的AI算法平台和仓库计划年底推出,该工具将极大降低AI开发门槛。在体验已有AI demo集的基础上,开发者可空中升级新增的AI算法demo 以及算法二次开发,并轻松优化部署在硬件上。
嘉楠科技的AI工具链,软件SDK等代码和文档已全面开源在Github等平台上,以勘智Kendryte AI品牌呈现。
三、存算一体核心力量集结!从小算力走向大算力
存算一体是当前AI芯片领域最热门的架构创新方向。这个有望突破传统算力瓶颈的创新赛道,不仅是国际芯片学术顶级会议的焦点话题,而且在产业界开始频频“吸金”,连获各路资本的倾投。
今天下午,五位国内存算一体AI芯片创企的创始人兼CEO齐聚GTIC 2022全球AI芯片峰会·存算一体芯片专题论坛,展示前沿架构与落地进展,探讨高能效、低成本的可行之径。
1、知存科技王绍迪:存内计算芯片能效、成本优势明显,WTM系列芯片率先布局生态
相比于传统计算架构,存算一体更适合AI计算。利用欧姆定律乘法的计算原理,这种架构就可以实现百万级、千万级并行计算,使得AI计算算力能效提升数倍到数十倍,相比CPU、GPU具备更高密度、更高并行度、更高能效、更大算力。
知存科技创始人兼CEO王绍迪谈道,存算一体在成本、算力、功耗上有很大优势,但还需要补齐通用型、工具链、精度。
 ▲知存科技创始人兼CEO王绍迪
▲知存科技创始人兼CEO王绍迪
知存科技已经量产商用存内计算SoC芯片WTM2101,AI算力达到50Gops,功耗仅5uA-3mA,主要应用于可穿戴场景中的语音识别、语音增强、健康监测等功能。未来5年内,还将发布更高算力芯片序列WTM8系列、WTM-C系列、WTM-S系列。
接下来,凭借存内计算产品研发和商用的先发优势,知存科技会持续投入算法体系、架构创新与工具链、底层工艺三个层面,推动存内计算生态构建。王绍迪表示,存内计算未来也要拥抱Chiplet,将兼容性、能效做的更好。
2、苹芯科技杨越:AI算力下沉时代,用SRAM突破“存储墙”限制
进入AI时代,算力正在下沉到移动物联网及AIoT终端,计算更加注重能耗及效率。
为了解决“存储墙”问题,减少数据在存储器与处理器之间的传输损耗,业界出现了CMOS加速器、近存计算、存内计算等多种路径。苹芯科技联合创始⼈兼CEO杨越认为,在可实现存内计算的多种存储器技术中,SRAM(静态随机存取存储器)具有较大计算优势。
 ▲苹芯科技联合创始⼈兼CEO杨越
▲苹芯科技联合创始⼈兼CEO杨越
聚焦这一领域,苹芯科技推出了SRAM数字存内计算内核,支持常见的定点/浮点运算,能实现超5倍效率提升,纳秒级读写延迟,无擦写次数限制,并且能够向高级工艺节点兼容,引入ADC-less设计,从而实现精度无损效果。从内核硬件到SoC产品,苹芯科技在可挂载的PIM核、软件构建等方面加大布局,目前正在陆续推出NE002、NE003、PIMCHIP S230等几款芯片。
权威报告显示,2030年全球AI芯片市场规模有望达到2021亿美元。杨越说,苹芯定位的市场不局限于AI识别算法,还覆盖了包括降噪算法、SLAM算法、ISP算法等其他矩阵类运算,目标落地智慧可穿戴、机器人、工农业智能化设备等领域。
3、亿铸科技熊大鹏:基于ReRAM的全数字化存算一体大算力芯片技术
AI芯片正在从通用CPU、专用加速器发展为存算一体阶段,而冯·诺依曼架构的存储墙、能效墙、编译墙正在阻碍AI芯片算力和能效比的持续发展。
亿铸科技创始人、董事长兼CEO熊大鹏谈道,存算一体架构在突破这些瓶颈上具有先天优势。目前实现存算一体架构主要通过模拟、数模两种方式。模拟能够提高两个数量级以上的能效比,数模混合能部分解决精度问题,不过这两种方式会牺牲部分精度,同时数模、模数转换会带来能耗、面积和性能瓶颈。
 ▲亿铸科技创始人、董事长兼CEO熊大鹏
▲亿铸科技创始人、董事长兼CEO熊大鹏
为了突破上述瓶颈,亿铸科技基于ReRAM打造了全数字化存算一体AI大算力芯片技术,通过数字化彻底解精度问题,在整个计算过程中,不受工艺环境的影响,实现高精度、大算力、超高能效比,切实将存算一体架构应用于大算力领域。
不同存储介质应用在不同场景上各有优劣势。熊大鹏认为,面向AI大算力场景,ReRAM是目前最合适的存储介质。亿铸选择ReRAM的优势在于非易失、密度大、密度上升空间巨大、能耗低、读写速度快、成本低、稳定、兼容CMOS工艺等特点。目前ReRAM的制造工艺已经成熟,且已经有ReRAM产品量产落地。
4、智芯科张钟宣:解决AI落地中的“将大象塞进冰箱”难题
杭州智芯科微电⼦创始⼈兼CEO张钟宣说,千千万万的AI公司做AI落地,面临“将大象塞进冰箱”的问题。例如,一个手机的功耗不能超过5W,否则热散不去,AI模型落地到手机上,就会损失很多效果。
 ▲杭州智芯科微电⼦创始⼈兼CEO张钟宣
▲杭州智芯科微电⼦创始⼈兼CEO张钟宣
看到这一市场发展瓶颈,智芯科选择基于SRAM(静态随机存取存储器)的存内计算技术,解决后摩尔时代的“大算力、低功耗”市场痛点。智芯科主要聚焦视觉处理芯片、GPNPU(通用神经网络处理器)两个落地方向。
张钟宣谈道,智芯科的视觉处理器AT700 AI CIM,int8能耗比达到10TOPS/W。AT700X Pre-ISP图像增强能使算力超过20TOPS,同时功耗低于1W;落地网络摄像机领域,能实现0.5~2W低功耗,算力达10~50TOPS(int8),实现暗光全彩效果;AT800 GP CIM是其代表性的边缘AI处理器,采用12nm制程,int8能耗比达到30TOPS/W,几乎达到当下5nm同类芯片的水平。
在软件方面,智芯科推出了一套AI工具流程,面向客户提供网络优化、量化浮点达int8的算力服务,并支持神经网络图形编译、可执行二进制文件生成的相关硬件。
5、九天睿芯刘洪杰:基于混合信号SRAM存算一体,多模态传感器协同
人机交互系统智能程度提升,带来了传感器数量、时间空间分辨率要求及神经网络应用规模的提升,对多维度数据同步采集、传输、处理、运算和存储操作的能效、面效和时效性能提出了更高的要求。
九天睿芯创始人、董事长兼CEO刘洪杰谈道,基于SRAM的混合信号存内计算能够实现更小的运算单元、更高的能效,同时保持符合商用的精度,体现了该架构良好的应用优势,在面积上,九天睿芯的产品大小仅为1.4×1.4平方毫米。
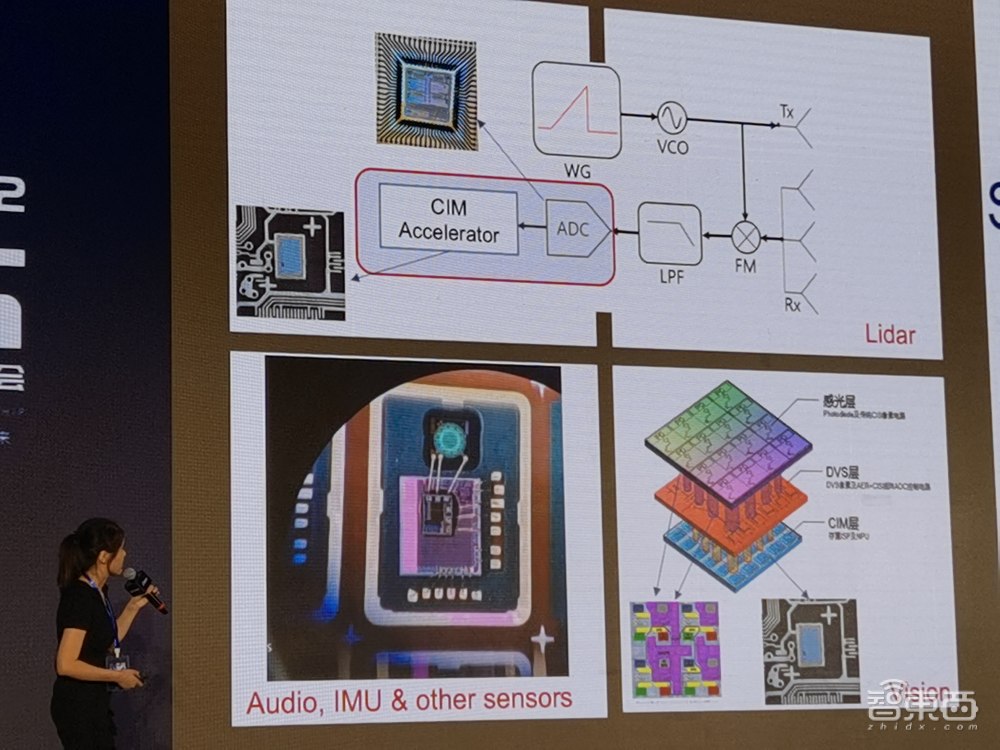 ▲九天睿芯创始人、董事长兼CEO刘洪杰
▲九天睿芯创始人、董事长兼CEO刘洪杰
混合信号SRAM存算一体同时结合模拟预处理和高性能ADC,九天睿芯使整个信号链更智能更高效率,这一架构能打破传感器端ADC速度和精度性能瓶颈,存算一体实现了NPU突破功耗瓶颈,因此适用于追求极致低功耗和低延时、高精度的场景。面向两个应用:1,VR/AR领域的未来应用,基于混合信号SRAM感存算一体可帮助实现眼动追踪,以及VR/AR头显设备的超低功耗语音识别、SLAM同步定位与构图。2,集成模拟预处理或高速ADC与存算一体的车用传感器端(视觉,激光雷达等)的低延时低功耗高集成度处理。
四、锻造新型计算钥匙,打开通用智能未来之门
在后摩尔时代,AI芯片日渐面临来自器件、工艺、架构、能耗、成本等诸多芯片设计与制造层面的挑战。同时,尽管 学习算法的落地愈发广泛,产学界仍在探索实现通用智能的更多可能路径,这要求AI芯片从底层架构创新,来应对主流AI算法变化的不确定性。
除了存算一体方兴未艾,还有几类新型计算架构走出学术象牙塔,走向产业化。在新型计算技术专题论坛上,类脑计算创企代表灵汐科技、光子计算创企代表曦智科技、量子计算创企代表玻色量子发表主题演讲,分享他们如何通过将前沿技术转化落地,闯向AI计算加速的“无人区”。
1、灵汐科技华宝洪:类脑芯片已量产落地,异构融合成新趋势
灵汐科技副总经理华宝洪认为,类脑计算是后摩尔时代颠覆性战略技术,已成中美欧科技竞争必争之地。这一方法受人脑启发产生,是一个融合生物脑科学原理和计算机科学原理的计算系统,具有近似计算、抗噪音、稀疏、时空相关性等特点。
 ▲灵汐科技副总经理华宝洪
▲灵汐科技副总经理华宝洪
华宝洪说,异构融合是类脑计算的发展趋势。灵汐科技的相关成果于2019年登国际学术顶刊《自然》封面,基于此灵汐科技已流片和量产了边端首款商用类脑芯片Lynchip KA200,兼容人工神经网络和生物神经网络,采用12nm制程,支持25万神经元、2500万突触,稀疏模式支持200万神经元,DNN算力达到32TOPS(int8),16TFLOPS(FP16),功耗范围在1-14瓦,运行ResNet50-64、yolo5等主流网络时,芯片在能效比和性价比远高于NVIDIA T4。
目前灵汐科技的类脑计算芯片已经用于脑科学和类脑计算,同时也覆盖安防、机器人、无人机等传统AI应用领域。
2、曦智科技胡永强:光电混合,重新定义算力基建
半导体工艺从硅基时代的10μm工艺发展到3nm工艺,进入后摩尔时代,企业开始探索光子计算、量子计算、存内计算的发展。曦智科技全球副总裁胡永强谈道,光子计算的底层优势是低延迟、低能耗、高通量。与电传输相比,光信号以光速传输,能实现微米至百米级的TB级数据传输能力。
 ▲曦智科技全球副总裁胡永强
▲曦智科技全球副总裁胡永强
基于光子矩阵计算oMAC、片上光网络oNET、片间光网络oNOC的三大光核心技术,曦智科技打造了光子计算和光子网络两大产品线。
相比于电子芯片,光的计算单元并行能力很强,可以利用波分复用同时计算多路数据,同时获得更高的能效比以及极低的计算延迟,且对工艺制程的要求也更低。此外,片上光网络oNOC技术将CMOS硅电子芯片堆叠在光芯片上,这种光电技术能通过光波导实现高带宽、低能耗、低延迟的chiplet网络互联方案。
去年,曦智科技发布了第二代光计算处理器PACE,采用64×64光学矩阵乘法器,单个光子芯片中集成超过10000个光子器件,其运行特定神经网络的计算速度可以达到目前高端GPU的数百倍。今年下半年,曦智科技将推出全球首颗基于oNOC技术的光电混合3D封装AI加速计算芯片,并搭载自研软件栈。
3、玻⾊量⼦⽂凯:光量子芯片正从理论优越性走向实用优越性
量子计算代表着下一代算力的重要突破方向。在量子计算世界中,运算的基本单元是量子比特,它的基本状态是0和1的叠加。对N个量子比特进行一次操作,相当于对经典比特进行2的N次方次操作。这体现了量子计算机的巨大运算潜力,可应用于模拟、优化、机器学习、密码学等方向。
玻色量子创始人兼CEO文凯分享说,光量子计算是商用化量子计算机的新形态,目前正从空间光发展到集成光学芯片,从理论优越性走向实用优越性。比如中科大“九章”去年研制的113个光量子的“九章2.0”完成了高斯玻色采样计算实验,比经典超级计算机快了大约10的24次方倍,验证了量子计算的理论优越性。近年来,北京大学王剑威团队、美国PsiQuantum公司,加拿大Xanadu公司等都进行了光量子计算芯片化的相关探索。
 ▲玻色量子创始人兼CEO文凯
▲玻色量子创始人兼CEO文凯
创立于2020年底的玻色量子是一支来自斯坦福大学、麻省理工、清华大学、中科院等学府的团队,多年研究基于DOPO(简并光学参量振荡器)的相干量子计算方案,并在量子神经元生成芯片、通用光量子计算芯片等方向展开了攻关。
目前,玻色量子已推出第一代“天工”光量子计算验证平台,在国内首次实现25节点任意相连可编程的MAX-CUT问题的优化求解验证,能在50微秒内在3000多万种可能性中筛选出4个最优解之一。在商业化场景应用上,玻色量子在金融、交通、生物制药等方面也都实现了突破。
结语:AI芯片长坡厚雪,奔向智能计算未来
至此,GTIC 2022全球AI芯片峰会圆满收官。
在这场AI芯片盛宴上,我们看到技术创新的力量依然熠熠生辉,从竞逐有效算力到聚焦解决现实问题,许多创新方案提供了更多破解AI芯片瓶颈的差异化思路,多个创业团队积淀的AI芯片实力也开始厚积薄发。
同时,我们也看到,无论是大算力还是小算力的AI芯片,无论是相对成熟的领域专用架构、通用GPU,还是存算一体、类脑计算、光子计算、量子计算等前沿技术路线,都有越来越多的高性能产品走向规模化量产与商用落地。
随着疫情得到有效控制,行业秩序逐步恢复,面对智能化、数字化、电动化带来的海量数据计算需求,承载着智能计算核心动力的AI芯片产业,继续快速奔跑,未来市场发展空间广阔。
我们希望GTIC 2022全球AI芯片峰会成为前沿技术交流和产业落地对接的平台,通过邀请各条细分赛道极具代表性的AI芯片企业们同台,共同谱出AI芯片产业的最强音。
预告:GTIC另一场产业峰会,2022全球自动驾驶峰会,也将于近期(9月27日)在深圳举行,敬请关注。















