在2021年的春季新品发布会上, 汉王发布了其手稿识别技术。基于 学习技术,在海量数据训练基础上,经多年研发,汉王科技突破性解决了自由书写文稿识别这一OCR领域难题,这是文字识别领域的一项重大技术突破。面对自由书写的文稿内容,利用此技术只要随手一拍,就可以秒级转换为文本。无论是背景干扰严重的复印纸、还是形状弯曲的纸稿,都可以轻松应对,真正做到了人眼可辨即可识。
作为业界最早致力于OCR识别技术研发和应用的公司之一,自2013年,汉王科技就将文档电子化的触角延伸至图书馆、档案馆,银行、医院、法院等多个国家级项目。在图书馆领域,汉王已与国家图书馆持续合作了十三个年头。从最初的图书扫描加工,到元数据加工,再到高精度全文加工;从简体中文识别,到繁体中文识别,再到高难度的古籍识别;从纸质文献到电子文献;从内容加工服务到管理平台建设,汉王 与国家图书馆合作,不断挑战新的业务高度。

但在此过程中,利用OCR技术仅仅是将纸质文档变成数字化文本,这样的电子文档没有对文本进行挖掘、知识之间缺乏关联,被电脑检索也只是对比相同字符搜集信息。要将海量的电子文档智慧化,就必须将文字信息形成结构化数据,只有形成结构化数据,信息和知识之间形成关联,才能为大数据应用服务,这涉及到人工智能技术中的自然语言处理技术(NLP),业界普遍认为,NLP是人工智能中最难的部分,也是决定AI是否智能的关键因素。
2015年,得益于 学习算法的快速进展,大规模社交文本数据以及语料数据的不断积累,NLP技术有了飞跃式的发展。汉王也顺势开始了其在NLP技术方面的布局。汉王科技与武汉大学的自然语言处理团队联合进行文档大数据化研发工作,力图突破NLP技术,建立起自己的文档大数据库体系,开发各种新的应用,主攻包括文本分类、聚类、结构化数据抽取、知识抽取、知识图谱、机器阅读等在内的NLP技术。
在对文史出版社丛书文献进行知识加工过程中,通过从文献中碎片化抽取、清洗、归集、融合得到基础数据, 加工挖掘得到人物、地点、机构、事件类的知识条目,再基于知识条目构建人物库、地点库、机构库、事件库等知识资源库,并通过关系定义实现跨类别的知识关联,提供了超越图书内容信息的 知识服务。
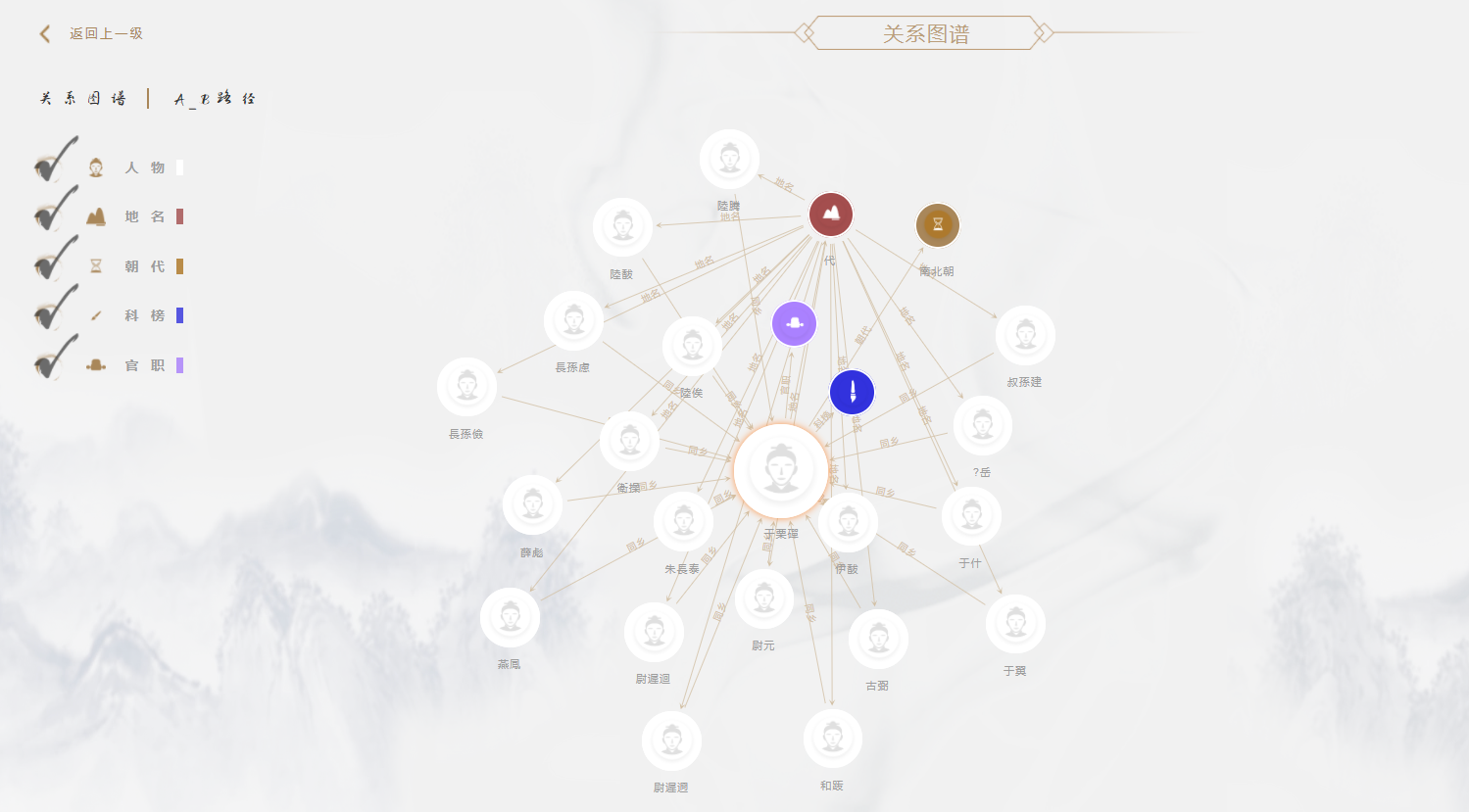
近日,在承接的国家图书馆"智慧图书馆体系建设项目"中,汉王针对民国文献数字资源开展知识化加工,完成数字资源精细化标引和知识内容抽取,细化文献颗粒度,多维度揭示文献的知识内容,并开展多维度、多层次知识组织,提供基于知识图谱的可视化展示。该项目实施过程中就应用到了包括基于 学习的新一代文字识别、自然语言理解、智能抽取、知识图谱构建、数据可视化等多项人工智能创新型技术。这将是双方在人工智能新时代,针对文化领域的一个重点创新与尝试,其成果将作为全国智慧图书馆体系建设的重要参考之一。
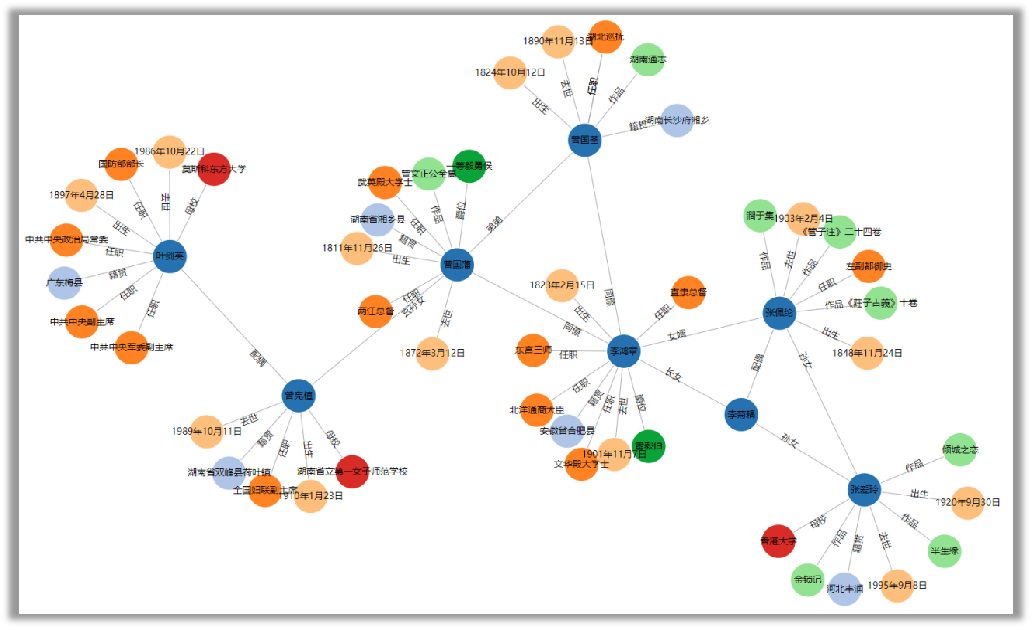
上图是汉王基于对民国史料海量数据的识别,利用NLP技术形成的知识图谱,,形成更为有效的智能化方式,提供智能搜索、 问答等,让知识“活起来”,更好的服务人民大众。据悉,汉王还为中华字库完成了8亿字的数字化工作。
在技术迭代升级中,汉王还推出了中英文双核心,英文手稿也做到了高精度识别。自由手写体95%以上的识别率、0.3秒/页的转换速度,至少是人工录入的500倍。一个资料室的手稿录入,需要50个人做10年,而利用汉王的技术只需要1台机器跑3个月。
汉王一直在手写OCR领域不断加速新算法开发,当前不仅可高精度识别满文,在藏文、日文、英文手写体识别方向均有突破,其中,日文手写识别支持7389字符集,并支持水平和竖直书写识别,识别率可达97%。
为进一步加强公共数字文化建设,提升全民阅读、全民艺术普及数字化服务水平,“十四五”时期,文化和旅游部面向公共图书馆系统组织实施全国智慧图书馆体系建设项目、面向文化馆系统组织实施公共文化云建设项目。近日,中央财政下达了2021年中央支持地方公共文化服务体系建设补助资金,为全国智慧图书馆体系建设项目、公共文化云建设项目安排了相关资金。相关资料显示,中国图书馆数字化市场达5000亿元,近几年来,汉王科技在其OCR与大数据业务板块上的可以说是大比例投入,面对当前方兴未艾的数字化浪潮,汉王科技的布局也是“小荷才露尖尖角”。随着国家数字化建设和市场的打开,大规模技术与行业红利将不断显现,汉王也将在这一赛道上或将迎来新一轮的增长。





















