近日(5.7-5.11),第十二届国际学习表征会议(ICLR)在奥地利维也纳的展览会议中心召开。
ICLR 2024 的论文终审工作自 1 月份启动以来,共收到了 7262 篇提交论文,相较于上一年度的 4966 篇,增幅达到了 46.1%,接近翻了一番。
在严格的评审过程中,大会最终接受了 2260 篇论文,整体接收率维持在 31%,与去年的 31.8% 基本持平,其中 Spotlights 和 Oral 两种类型的论文展示分别有 367 篇(占 5%)和 86 篇(占 1.2%)论文获选。
除了论文数量激增外,大模型(LLM)也成为今年 ICLR 的热门关键词之一。以 LLM 为研究主题的投稿论文数量暴涨,研究团队来自全球各地,涵盖多个细分方向,ICLR 也由此吸引了美国微软、谷歌、OpenAI、Anthropic、Meta,以及中国智谱、百度、面壁等多个科技团队的参会。
可以说,今年人工智能领域首个举办的 ICLR 不仅是一个传统的学术会议,也是全球工业界大模型团队正面较量的缩影。ICLR 2024 的截稿日期是 2023 年 9 月 28 日,但在过去的大半年,LLM 在 AI 领域依然狂飙不止。
更值得关注的是,从今年的 ICLR 论文成果与演讲来看,经过一年的研究,各家在大模型上的研究已经不只停留在 " 研究 OpenAI"、" 追赶 OpenAI" 的阶段。尤其是中国的研究团队,他们已经不再单纯模仿 OpenAI。
相反,LLM 的研究团队都不约而同地提出了自己对 AGI 的思考。
LLM 成为绝对主角
ICLR 是由 学习领军人物、图灵奖三巨头之二的 Yoshua Bengio 和 Yann LeCun 牵头发起的,首届会议于 2013 年在美国亚利桑那州的斯科茨代尔举办。
尽管与 NeurIPS(神经信息处理系统大会)和 ICML(国际机器学习大会)相比,ICLR 的年资尚浅,但其学术影响力和认可度正日益提升,现已与前两者一起被公认为机器学习领域的三大顶级会议,参会人数与投稿数量也逐年显著增加。
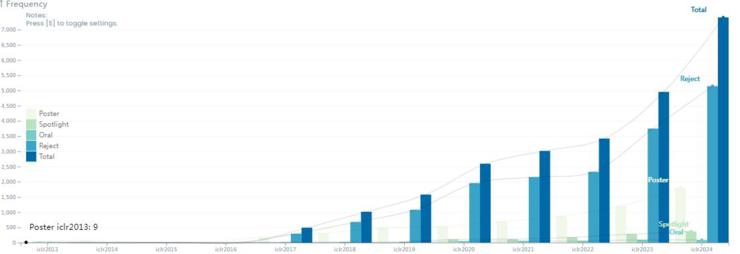 ICLR 历年数据:https://papercopilot.com/statistics/iclr-statistics/
ICLR 历年数据:https://papercopilot.com/statistics/iclr-statistics/
会议召开的前一天,ICLR 2024 的官方网站公布了本年度的获奖论文名单,特别表彰了 5 篇杰出论文和 11 篇荣誉提名论文。5 篇杰出论文主要围绕图像扩散模型、模拟人机交互、预训练和微调、离散蛋白质序列数据的建模与 Vision Transformers 展开研究,其中预训练与微调就是大模型相关。
根据 ICLR 公布的接收论文数据,被提及次数最多的前十个关键词分别是:大语言模型(LLM)、强化学习、图神经网络、扩散模型、 学习、表征学习、生成模型、联邦学习、语言模型与可解释性。
在这些关键词中,LLM 排名第一,被 318 篇研究提及,与位列第二名的强化学习(201 篇)相比,整整多了 1/3,毫无疑问成为 ICLR 的绝对主角。
 这 301 篇以 LLM 为研究主题的工作所涵盖的具体方向也十分广泛,如关于智能体(Agent)的研究、与强化学习结合、与其他生成模型结合、与三维重建结合、在 NLP 领域的应用、在多模态领域的应用、碳足迹建模等等。
这 301 篇以 LLM 为研究主题的工作所涵盖的具体方向也十分广泛,如关于智能体(Agent)的研究、与强化学习结合、与其他生成模型结合、与三维重建结合、在 NLP 领域的应用、在多模态领域的应用、碳足迹建模等等。
在被 ICLR 接收的 LLM 相关论文中,有不少过去几个月令人惊艳的新科研成果或产品,比如由 赋智等中国团队开发、开源的多 Agent 开发框架 MetaGPT。
MetaGPT 模拟了一个完整的虚拟软件团队,包括多个角色如产品经理和工程师,采用标准操作流程,旨在自动化编程任务,解决大模型应用问题,能输出设计、架构和代码。这篇论文在 ICLR 2024 中得到了 8.0 的高分。
普林斯顿大学和芝加哥大学联合发布的 LLM 评估框架 SWE-bench 也被选中为 Oral 论文。
这是一个由来自 GitHub 中真实的 2294 个软件工程问题以及 12 个流行的 Python 存储库中的拉取请求所组成的评估框架,通过给定代码库以及要解决的问题的描述,测评 LLM 编辑代码库解决问题的能力。
解决 SWE-bench 中的问题通常需要同时理解和协调多个函数甚至是文件之间的更改,调用模型与执行环境交互,处理极长的上下文,并执行远超出传统代码生成任务的复杂推理。可以说,这个测评标准的出现,让市面上大模型的性能比拼有了更直观的数据。
此外,还有 MIT、港中文及英伟达提出的超长上下文 LLM 高效微调方法 LongLoRA 。
这是一种十分有效的微调方法,通过稀疏的局部注意力进行微调, LongLoRA 实现了上下文扩展,节省了计算量,并具有与普通注意力微调相似的性能。
ICLR 2024 还出现了 LLM 与碳足迹的新颖结合。来自印第安纳大学与杰克逊州立大学的研究团队发现,能在训练前预测新神经网络的碳足迹的工具 mlco2 存在局限性,如无法估算密集或专家混合(MoE)LLM 的碳足迹,忽视关键架构参数,仅关注 GPU,且无法对具体碳足迹进行建模。
为解决这些局限,他们开发了一种专为密集和 MoE LLM 设计的、端到端碳足迹预测模型,显著提高了 LLM 碳足迹估算的准确性。
关于 LLM 与三维重建的结合,澳大利亚国立大学与 Adobe 研究中心提出的 LRM,能够在短短 5 秒内从单个输入图像预测对象的 3D 模型。
与以往在小规模数据集上训练的方法不同,LRM 采用高度可扩展的、基于 Transformer 的架构,拥有 5 亿个可学习参数,并可以直接从数据集预测神经辐射场(NeRF)。研究团队在大约包含 100 万个对象的海量多视图数据上以端到端的方式训练了 LRM,包括来自 Objaverse 的合成渲染和来自 MVImgNet 的真实截图。
无论是 MetaGPT 还是 LongLoRA,国内大模型的研发人员均参与其中,放眼望去,入选的华人作者更是比比皆是。
而来到 ICLR 2024 的大会现场,中国的大模型初创团队如智谱 AI,互联网科技大厂如字节、百度、美团、华为、蚂蚁的身影更是遍布在展会各处,在 32 个参会企业中占领了其中的 6 席。
Keynote 演讲中,智谱等来自中国的大模型公司也作了深入分享,吸引了来自国内外 LLM 参会者的广泛关注。
 不难发现,中国团队已成为大模型研究热潮中不可忽视的主力军。
不难发现,中国团队已成为大模型研究热潮中不可忽视的主力军。
从 ICLR 看见 " 中国 AGI"
2023 年 ChatGPT 引爆大模型热潮后,AGI 就成为了备受关注的焦点议题。如何通往 AGI,成为了无论是技术驱动、产品驱动还是商业驱动团队都要争相回答的问题。
从 GPT-3 到 GPT-3.5,从 ChatGPT 到 GPT-4 与 GPT-4V,OpenAI 的下一步 "GPT-X" 一度成为行业最热的话题猜测,并曾被狂热地视为 "LLM 的下一步 "。
然而,随着越来越多的研究者加入,中国的大模型研究者开始批判思考 "OpenAI 模式 " 与 "GPT 路线 "。据 AI 科技评论与多个中国大模型团队的交流,他们越来越相信,如果一味追赶 OpenAI,那么 " 我们将最多成为 OpenAI,却无法超越 OpenAI"。
比如,有大模型团队指出,大模型不具备 " 智能涌现 " 的能力,一味追求通过扩大模型规模来实现模型智能的路线风险极高,大模型要通过具体的产品与服务来实现价值。2023 年斯坦福团队获选 NeurIPS 最佳论文的工作 "Are Emergent Capabilities of LLMs a Mirage?" 就指出,大模型的智能涌现能力也许是错觉。
OpenAI 的单向路线以及过度依赖长序列的方法,也引起行业的反思。以长文本为例,如果说大模型的目标是实现 AGI,那么从 AGI 的终极目标倒推,AGI 所应包含的能力并不是 OpenAI 大模型的现有架构所能很好解决的。类比人类的能力,人会通过多次做一件事、越做越熟练,且掌握一项技能(如骑自行车)后就不会遗忘,但目前的大模型并不具备类似人的这种 " 经验性记忆 ",长文本与长序列目前也没有显示出表达这种能力的潜力。
相比模仿 OpenAI,中国的大模型创业者开始趋于从 AGI 的第一性原理出发,思考一条独特的、同时符合中国市场与服务的技术路线。
即使是被外界视为从模型到产品全面对标 OpenAI 的智谱 AI,在如何实现 AGI 的路径上也有与 OpenAI 不同的思考。这一差异在智谱团队于 ICLR 2024 大会现场发表的主旨演讲内容中可见一斑。作为唯一受邀作主旨演讲的中国 LLM 团队,智谱在 ICLR 围绕 "ChatGLM 的 AGI 之路 " 分享了团队的独特思考。
尽管模型矩阵与 OpenAI 相似,但智谱的 AGI 核心与路径却大大区别于 OpenAI。
 从 2019 年开始,智谱的大模型研究以 " 认知 "(Cognition)为核心,借鉴人类思维,将模型的能力研发分为负责快速直觉的 " 系统 1" 与负责慢速逻辑的 " 系统 2"。这借鉴了 Yoshua Bengio 最早提出的 "System 1" 与 "System 2" 理论。
从 2019 年开始,智谱的大模型研究以 " 认知 "(Cognition)为核心,借鉴人类思维,将模型的能力研发分为负责快速直觉的 " 系统 1" 与负责慢速逻辑的 " 系统 2"。这借鉴了 Yoshua Bengio 最早提出的 "System 1" 与 "System 2" 理论。
智谱的思考是:系统 1 以 LLM 为核心,能迅速响应简单问题;系统 2 则采用知识图谱构建,能处理复杂的推理任务,建立短期和长期记忆,还具备无意识学习和自我管理等功能。这是为了让计算机程序能像人类运用左右脑一样,既能快速回答简单问题,又能通过推理回答复杂问题。
此外,智谱的 GLM 大模型采取双向自回归路线,而 OpenAI 的 GPT 系列采取单向自回归路线。双向自回归的特点是:在生成 token 时,GLM 可以只关注单侧的上下文;在采用随机化的 token 控制策略处理已知 token 时,GLM 又能同时考虑两侧的上下文,实现对单向和双向注意力机制的双重管理。
这相当于将 BERT 的填空功能与 GPT 的生成能力相结合,通过自回归的方式做 " 完形填空 "。因此,在某些任务,GLM-130B 的性能能超过 GPT-3。
此外,智谱的大模型技术团队还认为,人类大脑具有多模态的感知与理解能力,以及短期和长期记忆能力以及推理能力的组合。因此,视觉语言模型(VLM)也是通往 AGI 不可缺少的一环。
CogVLM 就此诞生。这是一个开源的图像理解模型,旨在弥合 LLM 与视觉编码器之间的差距。通过将文本信息与视觉编码相结合,并对该组合模块进行训练,CogVLM 实现了文本与图像间精确的映射,极大地提升了模型对视觉内容的理解和生成能力,也被用于 Stable Diffufion 3 的图像标注。
技术团队还研发了一个创新级联框架 CogView3。作为第一个在文本到图像生成领域实现级联扩散的模型, CogView3 在人类评估中比当前最先进的开源文本到图像扩散模型 SDXL 性能高出 77.0%,推理时间却仅为其大约一半的长度,其蒸馏变体在性能相当的情况下,甚至只需 SDXL 的 1/10 的推理时间。
随着 CogVLM 的加入,GLM-4V 也投入了使用,无论是面对包含世界常识的图片还是需要理解推理的图表,GLM-4V 都能提供言之有物的回复。
为了让 GLM-4V 能自动产生不同的功能,如增加长文本的模式以储存长期记忆,或从反馈中不断自我学习完善,GLM 大模型技术团队开发了能为 LLM 启用通用代理(Agent)能力的 AgentTuning。
此前,大模型训练是通过输入数据让其不断学习和微调,但这个方法的缺点是它无法推广至其他更广泛的情况。而 AgentTuning 只需用少量案例和有限的标记数据,就可以将训练好的模型推广到不同的模型之中。
与此同时,大模型的 " 涌现能力 " 同样是智谱技术团队一直在探索的问题。在 LLM 烈火烹油的几年间,Scaling Law 被封为铁律,不少人认为模型大小与训练数据量的增加才能让模型 " 智能涌现 "。
OpenAI 科学家 Jason Wei 于 2022 年在机器学习期刊 TMLR 上发表了论文,提出 LLM 涌现能力中的某些能力仅在大模型中显现,小模型并不具备,因此大模型的新兴能力无法仅凭小模型的性能来预测,而增加模型的规模后,新兴能力自然会呈线性提高。
而智谱在不久前发布的研究却提出了一个新的理解:损失(Loss)才是涌现的关键,而非模型参数。
将训练损失标为 X 轴、模型性能标为 Y 轴后,研究人员发现,如果训练损失达到了 2.2 的阈值,模型性能就会攀升。由此可见,模型的 " 涌现能力 " 除了与模型大小、训练数据量紧密关联,也可能源自于训练损失。
 论文地址:https://arxiv.org/pdf/2403.15796.pdf
论文地址:https://arxiv.org/pdf/2403.15796.pdf
可以预见,GLM 系列将迎来新升级,GLM-4.5 及其后续版本将融合超级智能(SuperIntelligence)和超级对齐(SuperAlignment)技术,在增强模型的安全性的基础上构建全面的多模态模型。而这些成果的迭代,都是源于一个团队的创新思考。
在 ICLR 大会演讲中,智谱提出了自己的 AGI 思考:
首先是在文本这一最关键的智能基础上混合图像、视频、音频等多种模态,将 LLM 应用于聊天、OCR 识别等场景中;接着开发虚拟的 Agent 来协助用户完成多种任务,再之后是开发能与现实世界互动并得到其反馈的 Agent,接下来甚至可能是机器人,通过机器人和现实世界互动后得到真实反馈、以进一步实现 AGI ……
智谱团队还提出了一个有意思的概念:GLM-OS。
在他们的设想中,这是一个以大模型为核心的通用计算系统,能利用现有的 All-Tools 功能,结合记忆和自我反馈机制,模拟人类的计划 - 执行 - 检查 - 行动(Plan-Do-Check-Act, PDCA)循环,实现自我优化。这一设想引起会议观众的热烈关注,也展示了中国大模型团队的前瞻性与思考力。
最后,团队分享了自 2019 年起研发的 GLM-zero 技术,该技术探索了类似人类在睡眠中仍进行学习的无意识学习机制,涉及自我引导、反思和批评,旨在深化对意识、知识和学习行为的理解,也代表了 AGI 的重要一步。
值得关注的是,在今天,能调用以上技术 API 的智谱大模型 MaaS 开放平台(bigmodel.cn)就大幅降价,其中最具性价比的基座大模型 GLM-3-Turbo 模型的调用价格下调 80%,从 0.005/ 千 tokens 降至 0.001/ 千 tokens,新注册用户获赠还从 500 万 tokens 提升至 2500 万 tokens(包含 2000 万入门级额度和 500 万企业级额度)。

写在最后
今天,Sam Altman 预告 OpenAI 将在 5 月 13 日发布新产品,既不是万众期待的 GPT-5,也不是前段时间广为流传的 ChatGPT 搜索引擎产品。在海内外大模型仍在追赶 GPT-4 之际,OpenAI 又要开拓新的版图。
" 追赶 OpenAI,成为 OpenAI,超越 OpenAI。" 这似乎已成为国产大模型的魔咒。
但在过去一年,智谱 GLM-4、阿里 Qwen-Max 与百度文心一言 4.0 等国产大模型在各类评测榜单表现亮眼,跻身于国际舞台。此次 ICLR 大会现场的 LLM 成果就已表明,2024 年," 追赶 OpenAI" 不再是中国大模型公司的核心," 超越 OpenAI" 与商业化落地才是国内团队的目标。
对比 2012 到 2022 的 学习十年,我们不难发现,大模型时代的 AI 发展周期在不断加快。在加速的技术周期中,技术从研发到商业的距离也大幅缩减,对创新者也不断提出了新的要求。
" 没有第二个 OpenAI",但有 " 第一个 ChatGLM"、第一个文心一言、第一个通义千问……也许从前国内行业观察者信心不足,但 ICLR 2024 结束后,国产大模型的力量走出国门,能与国际知名的 LLM 公司较量——这一事实,会更加振奋国内 LLM 的信心。
本文雷峰网作者 anna042023 将持续关注 AI 大模型领域的人事、企业、商业应用以及行业发展趋势,欢迎添加雷峰网作者交流,互通有无。
来源:雷锋网















