在OpenAI文生视频大模型Sora发布后,国内企业争相入局,国产文生视频大模型迈入加速阶段。近日,又一国产视频大模型加入战局,快手“可灵”视频生成大模型官网正式上线。相较此前各家放出的视频大模型以展示视频为主,本次亮相的可灵大模型不但效果对标Sora,且已在快手旗下的快影App开放邀测体验。
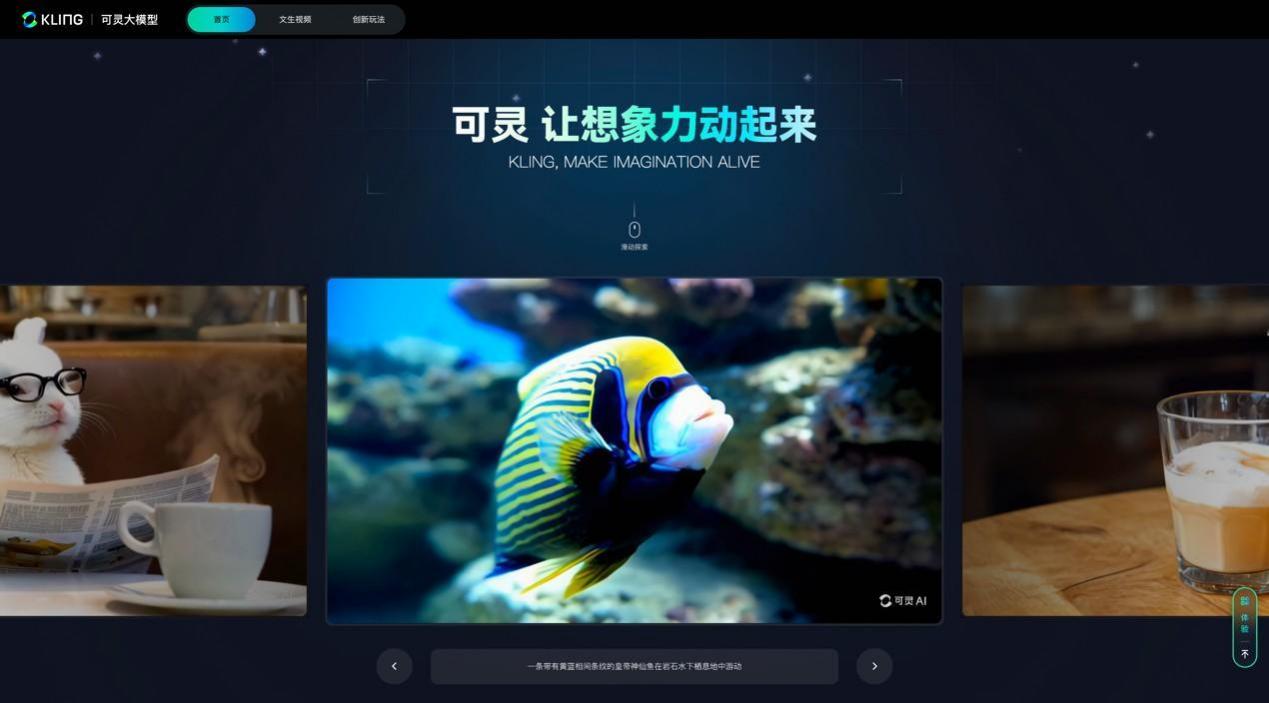
可灵大模型官网
作为短视频领域头部玩家,快手在短视频视频技术方面有多年的深入积累,其视频生成大模型也有天然、广泛的应用场景。可灵大模型为快手AI团队自研,采用类Sora的技术路线并结合多项自研创新技术,具备诸多优势:1、能够生成大幅度的合理运动;2、能够模拟物理世界特性;3、具备强大的概念组合能力和想象力;4、生成的视频分辨率高达1080p,时长高达2分钟(帧率30fps),且支持自由的宽高比。具体而言:
可灵大模型能够生成大幅度的合理运动。可灵采用了3D时空联合注意力机制,能够更好地建模视频中的复杂时空运动。因此,可灵大模型不仅能够生成较大幅度的运动,且更符合客观运动规律,能够真正做到让想象力动起来。下面宇航员在月球上奔跑的例子中,随着镜头慢慢抬升,我们可以看到宇航员跑步的动作流畅轻盈,步态和影子的运动合理恰当。

prompt:一名宇航员在月球表面奔跑,低角度镜头展现了月球的广阔背景,动作流畅且显得轻盈
能够模拟真实物理世界的特性。得益于自研模型架构及Scaling Law激发出的强大建模能力,可灵大模型为我们构建起了一个无限逼近现实的想象空间,无论是真实世界的光影反射,重力影响下的流体运动,还是与物理世界的交互,可灵大模型都能够生成符合物理规律的视频。下面是小男孩吃汉堡的生成视频,一口咬下去,汉堡被咬掉一个大大的缺口,并在视频中一直保持。可以看到小孩咀嚼汉堡的享受表情,脸部的肌肉动态非常逼真。

prompt:一个戴眼镜的中国男孩在快餐店内闭眼享受美味的芝士汉堡
具备强大的概念组合能力和想象力。凭借模型对文本-视频语义的深刻理解和基于 Diffusion Transformer 架构学到的强大概念组合能力,可灵大模型能够将用户丰富的想象力转化为具体的画面,让创意触手可及。下面的视频展示了熊猫吉他手坐在湖边弹着吉唱着歌的想象场景。

prompt:一只大熊猫在湖边弹吉他
可灵大模型生成的视频分辨率高达1080p、时长高达2分钟(帧率30fps),且支持自由的输出视频宽高比。可灵大模型的自研3D VAE能够将视频编码到紧凑的隐空间并解码成带有丰富细节的视频,可以生成高达1080p分辨率30fps的视频。得益于高效的训练基础设施、极致的推理优化和可扩展的基础架构,可灵大模型能够生成长达2分钟的视频。在推理过程中,还可以做到同样内容输出多种视频宽高比。下面的视频展示了分钟级的视频生成,我们可以跟随镜头,陪伴小男孩骑自行车游览花园,在一镜到底中欣赏春夏秋冬四季的风景。

(完整视频详见可灵官网)
大模型的生成效果取决于数据的规模和质量、以及大规模训练的效率。可灵大模型在研发过程中,配套建设了高效的大规模自动化数据解决方案,覆盖了海量视频挖掘、多维打标筛选、视频描述增强、及数据驱动的效果质量评估等多个方面。在训练过程中,采用了多种计算优化和通信优化方案,极大提升了GPU和网络带宽利用率,并通过自动故障检测和failover等机制,提供了分钟级故障恢复能力。保障了短时间内模型效果的快速提升。
快影App的AI创作功能中已正式开放文生视频功能的邀测,支持创作者申请并体验可灵大模型最新的文生视频功能。图生视频功能也将于近期开放。
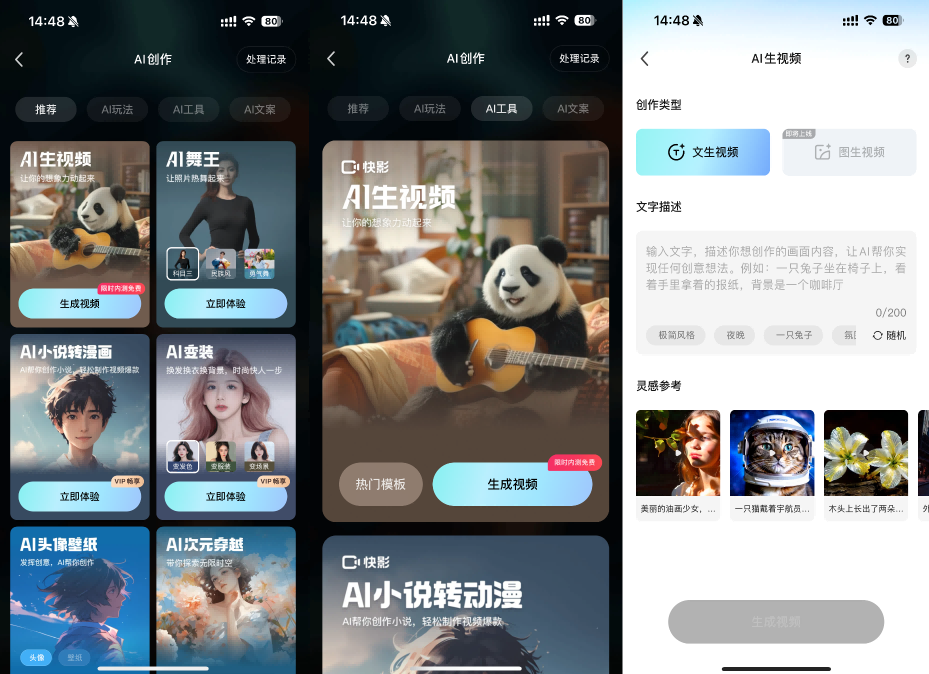
快影App还将在近期开放图生视频功能。基于可灵大模型,更多应用方向也已经或即将落地。例如,基于肢体驱动的“AI舞王”功能已在快手和快影App成功落地,用户只需上传一张全身或半身照片,即可体验一键跳舞的乐趣。近期还将首发上线“AI唱跳”新玩法,可以同时驱动表情和肢体动作,仅需一张照片就能生成唱跳“爱你”的生动视频。

随着AI大模型时代来临,作为头部短视频公司,快手已展开全面布局。公开资料显示,快手已先后发布通用大语言模型“快意”、文生图大模型产品“可图”,还推出了Direct-a-Video、Video-LaVIT、I2V-Adapter、UNIAA等视频关键技术,引发了广泛关注。据悉,伴随此次可灵大模型的发布,快手将持续加速大模型的研发与应用,带来更加多元的AI创作与互动体验。















