整理 | 兆雨
精准的推荐系统模型是很多互联网产品的核心竞争力,个性化推荐系统旨在根据用户的行为数据提供“定制化”的产品体验。国民级短视频App快手,每天为数亿用户推荐百亿的视频,遇到的挑战之一是推荐系统模型如何精准地描述与捕捉用户的兴趣。
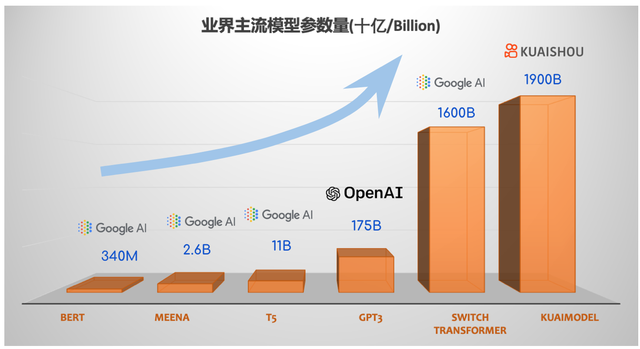
如今业内采用的解决方案通常为结合大量数据集和拟合参数来训练 学习模型,如此一来让模型更加逼近现实情况。Google日前发布了首个万亿级模型 Switch Transformer,参数量达到1.6万亿,其速度是Google之前开发的最大语言模型(T5-XXL)的4倍。然而快手万亿参数精排模型总的参数量超过1.9万亿,规模更大,且已经投入实践。下面就让我们通过快手精排模型的发展史,一起揭秘它内部的的技术密码吧!
图示:
Google BERT-large NLP预训练模型: 3.4亿参数量
Google Meena开域聊天机器人:26亿参数量
Google T5预训练模型: 110亿参数量
OpenAI GPT3语言模型:1750亿参数量
Google Switch Transformer语言模型: 16000亿参数量
快手精排排序模型:19000亿参数量
参数个性化CTR模型-PPNet
2019年之前,快手App主要以双列的瀑布流玩法为主,用户同视频的交互与点击,观看双阶段来区分。在这种形式下, CTR预估模型变得尤为关键,因为它将直接决定用户是否愿意点击展示给他们的视频。彼时业界主流的推荐模型还是以DNN,DeepFM等简单的全连接 学习模型为主。但考虑到某用户个体和视频的共建语义模式在全局用户的共建语义模式基础上会有个性化的偏差,如何在DNN网络参数上为不同用户学习一个独有的个性化偏差成为了快手推荐团队优化的方向。
在语音识别领域中,2014年和2016年提出的LHUC算法(learning hidden unit contributions)核心思想是做说话人自适应(speaker adaptation),其中一个关键突破是在DNN网络中,为每个说话人学习一个特定的隐式单位贡献(hidden unit contributions),来提升不同说话人的语音识别效果。借鉴LHUC的思想,快手推荐团队在精排模型上展开了尝试。经过多次迭代优化,推荐团队设计出一种gating机制,可以增加DNN网络参数个性化并能够让模型快速收敛。快手把这种模型叫做PPNet(Parameter Personalized Net)。据快手介绍,PPNet于2019年全量上线后,显著的提升了模型的CTR目标预估能力。

PPNet结构图
如上图所示,PPNet的左侧是目前常见的DNN网络结构,由稀疏特征(sparse features)、嵌入层(embedding layer)、多神经网络层(neural layer)组成。右侧是PPNet特有的模块,包括Gate NN和只给Gate NN作为输入的id特征。其中uid,pid,aid分别表示user id,photo id,author id。左侧的所有特征的embedding会同这3个id特征的embedding拼接到一起作为所有Gate NN的输入。需要注意的是,左侧所有特征的embedding并不接受Gate NN的反传梯度,这样操作的目的是减少Gate NN对现有特征embedding收敛产生的影响。Gate NN的数量同左侧神经网络的层数一致,其输出同每一层神经网络的输入做element-wise product来做用户的个性化偏置。Gate NN是一个2层神经网络,其中第二层网络的激活函数是2 * sigmoid,目的是约束其输出的每一项在[0, 2]范围内,并且默认值为1。当Gate NN输出是默认值时,PPNet同左侧部分网络是等价的。经实验对比,通过Gate NN为神经网络层输入增加个性化偏置项,可以显著提升模型的目标预估能力。PPNet通过Gate NN来支持DNN网络参数的个性化能力,来提升目标的预估能力,理论上来讲,可以用到所有基于DNN模型的预估场景,如个性化推荐,广告,基于DNN的强化学习场景等。
多目标预估优化-基于MMoE的多任务学习框架
随着短视频用户的需求不断升级,2020年9月,快手推出了8.0版本。这个版本里增加了底部导航栏,在此基础上增加了一个“精选”tab,支持单列上下滑的形式。这个兼容双列点选和单列上下滑的版本,旨在为用户提供更好的消费体验,加入更多元的消费方式。在新的界面下,有相当一部分用户会既使用双列也使用单列。用户在这两种页面上的消费方式和交互形式都有很大的不同,因此在数据层面表示出来的分布也非常不同。如何将两部分数据都用在模型建模里,而且用好,成为了快手推荐团队一个亟待解决的问题。
快手团队发现,当单列业务的场景增多后,多任务学习更加重要。因为在单列场景下,用户的交互行为都是基于show给用户的视频发生,并没有像双列交互那样有非常重要的点击行为。这些交互行为相对平等,而且这些行为数量多达几十个(时长相关预估目标、喜欢、关注、转发等)。

精排模型预估目标(部分)
随着单列业务数据量越来越大,从模型层面,推荐团队尝试拆离出针对单列业务单独优化的模型。具体表现在特征层面,可以完全复用双列模型特征,只是针对单列的目标,额外添加个性化偏置特征和部分统计值特征。在Embedding层面,因为前期单列数据量少,不能保证embedding收敛,最初使用双列数据click行为主导训练,后面改用单双列用户视频观看行为(有效播放、长播放、短播放)主导训练embedding。在网络结构层面,主要基于shared-bottom网络结构训练,不相关目标独占一个tower,相关目标共享同一tower顶层输出,这能在一定程度上提升目标预估效果。这个模型上线后,起初有一定的效果,但很快暴露出了一些问题。首先,它没有考虑到单双列业务中embedding分布差异,造成了embedding学习不充分。其次,在多任务学习层面,单列场景下,用户的交互都是基于当前视频show的单阶段行为,各个目标之间互相影响,模型单个目标的提升,不一定能带来线上的整体收益。
因此,如何设计一个好的多任务学习算法框架,让所有预估目标都能提升变得非常关键。这个算法框架必须考虑数据、特征、embedding、网络结构以及单列用户交互特点。经过充分的调研和实践,推荐团队决定采用MMoE模型(Multi-gate Mixture-of-Experts)来改进当前模型。
MMoE是Google提出的一种经典多任务学习算法,其核心思想是把shared-bottom网络替换为Expert层,通过多个门控网络在多个专家网络上上分别针对每个目标学习不同专家网络权重进行融合表征,在此融合表征的基础上通过task网络学习每个任务。
通过参考MMoE算法和上面提到的快手推荐场景难点,推荐团队改造了MMoE算法并设计了一套新的多任务学习算法框架。具体体现在,在特征层面,进行了语义统一,修正在单双列业务中语义不一致特征,添加针对用户在单列相关特征。在Embedding层面,进行了空间重新映射,设计了embedding transform layer,直接学习单双列embedding映射关系,帮助单双列embedding映射到统一空间分布。在特征重要性层面,设计了slot-gating layer,为不同业务做特征重要性选择。
通过以上3点的改动,模型将输入层的embedding表示从特征语义,embedding在不同业务分布,特征在不同业务重要性三个层面做了归一化和正则化,重新映射到统一的特征表征空间,使得MMoE网络在此空间上更好的捕捉多个任务之间后验概率分布关系。通过此项对MMoE的改进,模型所有的目标提升非常显著。
短期行为序列建模-Transformer模型
在快手的精排模型中,用户历史行为特征非常重要,对刻画用户兴趣的动态变化有很好的表征。在快手的推荐场景下,用户的行为特征非常丰富并且多变,其复杂度远远超过视频类特征或者上下文的特征,因此设计一个能够针对用户行为序列有效建模的算法很有必要。
目前业界上对于用户行为序列建模主要分为两种模式,一是对于用户的历史行为进行weighted sum,二是通过RNN之类的模型进行时序建模。在快手前期的双列精排模型里,用户行为序列只是简单做sum pooling作为模型输入。而在单列场景下,用户被动接收快手推荐视频,而且丢失掉封面信息后,用户需要观看视频一段时间再做反馈,因此主动视频选择权降低,更加适合推荐系统对用户的兴趣做E&E(Exploit & Explore)。
快手的序列建模灵感来自于Transformer模型。Transformer模型是Google在2017年提出的经典神经网络翻译模型,后来火爆的BERT和GPT-3也是基于此模型部分结构。Transformer主要包括Encoder跟Decoder两部分,其中Encoder部分对输入语言序列进行建模,这部分跟用户行为序列建模目标是非常类似的,因此快手借鉴其中算法结构并对计算量进行了优化。

MMoE结合Transformer建模用户兴趣序列
首先,快手推荐团队使用用户的视频播放历史作为行为序列。候选的序列有用户长播历史序列,短播历史序列,用户点击历史序列等,此类列表详尽地记录了用户观看视频id,作者id,视频时长,视频tag,视频观看时长,视频观看时间等内容,完整描述用户的观看历史。其次,对视频观看距今时间做log变换代替position embedding。在快手的推荐场景下,用户短期的观看行为跟当次预估更相关,长时间观看行为更多体现用户的多兴趣分布,使用log变换更能体现这种相关性。最后,替换multi-head self-attention为multi-head target attention,并且使用当前embedding层的输入作为query。这样设计的目的有两点,首先当前用户特征,预估视频特征和context特征比单独的用户行为序列提供更多信息。其次可以简化计算量,从O(d*n*n*h)变换为O(d*n*h + e*d),其中d为attention的维度,n为list长度,h为head个数,e*d表征的是embedding层维度变换为attention维度所需的复杂度。
改造后的Transformer网络能显著提升模型的预估能力,在离线评估上,用户观看时长类预估提升非常明显,线上用户观看时长也显著提升。
长期兴趣建模
长期以来,快手的精排模型都比较偏向于使用用户最近的行为。上面已经说到,通过采用transformer和MMoE模型,快手的精排模型对用户的短期兴趣进行了精确的建模,取得了非常大的收益。之前的模型里,采用了用户最近几十个历史行为进行建模。由于短视频行业的特点,最近几十个历史行为通常只能表示用户很短一段时间内的兴趣。这就造成了模型过度依赖用户的短期行为,而导致了对用户中长期兴趣建模的缺失。
针对快手的业务特点,快手推荐团队对于用户长期兴趣也进行了建模,使得模型能对于用户长期的历史记录都有感知能力。快手推荐团队发现,将用户的交互历史序列(播放、点赞、关注、转发等)扩长之后,模型能够更好的捕捉到一些潜在的用户兴趣,即使此类行为相对稀疏。针对该特点,推荐团队在之前的模型基础上设计并改进了用户超长期兴趣建模模块,能够对用户几个月到一年的行为进行全面的建模,用户行为序列长度能达到万级。此模型已经在全量业务推全并且取得了巨大的线上收益。

快手用户长期兴趣精排模型结构示意图
千亿特征,万亿参数
随着模型的迭代, 学习网络的复杂度越来越高,模型中添加的特征数量也越来越多,模型特征规模的大小也制约了精排模型的迭代。这不仅会限制模型特征的规模,使得一部分特征被逐出,带来模型收敛的不稳定性,同时还会导致模型更容易逐出低频的特征,造成线上冷启动效果变差(新视频、新用户),对于长尾的视频或者新用户不够友好。
为了解决这个问题,快手推荐和架构的同学针对训练引擎和线上serving进行改进,做到离线训练和线上serving的服务根据配置的特征量灵活扩展,可以支持精排模型离线跟线上有千亿特征,万亿参数的规模。特别的,新模型对于新视频跟新用户的流量分发更加友好,在新用户和新视频的指标上有显著的提升,践行了快手推荐”普惠“的理念。目前快手的精排模型,总特征量超过1000亿,模型总的参数量超过19000亿。
在线训练和预估服务
为了支撑推荐场景下千亿特征模型的在线训练和实时预估,推荐团队针对训练框架和线上预估服务的参数服务器(Parameter Server)进行了修改。在推荐模型的在线学习中,存储Embedding的参数服务器需要能够精准的控制内存的使用,提升训练和预估的效率。为了解决这一问题,推荐团队提出了无冲突且内存高效的全局共享嵌入表(Global Shared Embedding Table, GSET)的参数服务器设计。

每个 ID 单独映射一个Embedding向量很快就会占满机器的内存资源,为了确保系统可以长期执行,GSET 使用定制的 feature score 淘汰策略以控制内存占用量可以始终低于预设阈值。传统的缓存淘汰策略如 LFU、LRU 只考虑了实体出现的频率信息,主要用以最大化缓存的命中率。feature score 策略考虑了机器学习场景下额外的信息来辅助进行特征淘汰。
在推荐系统的在线学习过程中,会有大量低频 ID 进入系统,这些低频 ID 通常在未来的预估中根本不会出现,系统接收了这些特征后可能很快又会再次淘汰他们。为了防止低频 ID 无意义的进入和逐出对系统性能产生影响,GSET 中支持一些特征准入策略来过滤低频特征。同时为了提升GSET的效率和降低成本,快手还采用了新的存储器件 -- 非易失内存 (Intel AEP)。非易失内存能提供单机达到若干TB的近似内存级别访问速度。为了适配这种硬件,推荐团队实现了底层KV引擎NVMKV来支撑GSET,从而很好的确保了万亿参数模型的线上稳定性。
展望未来
据快手推荐算法负责人,曾在Google Research担任Staff Research Manager的宋洋博士介绍,短视频行业有其独特的挑战,表现在用户量多,视频上传量大,作品生命周期短,用户兴趣变化快等多个方面。因此短视频推荐很难照搬传统视频行业精细化运营的做法,而需要依靠推荐算法对视频进行及时的,精确的分发。快手推荐算法团队一直针对短视频业务进行 定制和积极创新,提出了很多业界首创的推荐模型和想法,同时也给推荐工程架构团队带来了很多系统和硬件层面的挑战。
宋洋博士认为,快手精排万亿参数模型是推荐系统一个里程碑式的突破,它结合了序列模型,长短期兴趣模型,门控模型,专家模型等各个方面的优点,是至今为止工业界最全面,最有效的推荐模型之一。该模型已在快手的主要业务上全量上线为用户服务。在未来“算法-系统-硬件”三位一体的挑战和机遇可能会有更多,希望这将更进一步推动快手推荐系统在技术上的创新和突破,为用户增进体验和创造价值。