特斯拉渴望成为世界领先的人工智能公司之一。迄今为止,他们还没有部署最先进的自动驾驶技术;这一荣誉适用于 Alphabet 的 Waymo 。此外,在生成式人工智能世界中,特斯拉也不见踪影。话虽如此,由于数据收集优势、专业计算、创新文化和领先的人工智能研究人员,他们可能拥有在自动驾驶 和机器人技术领域实现跨越式发展的秘诀。
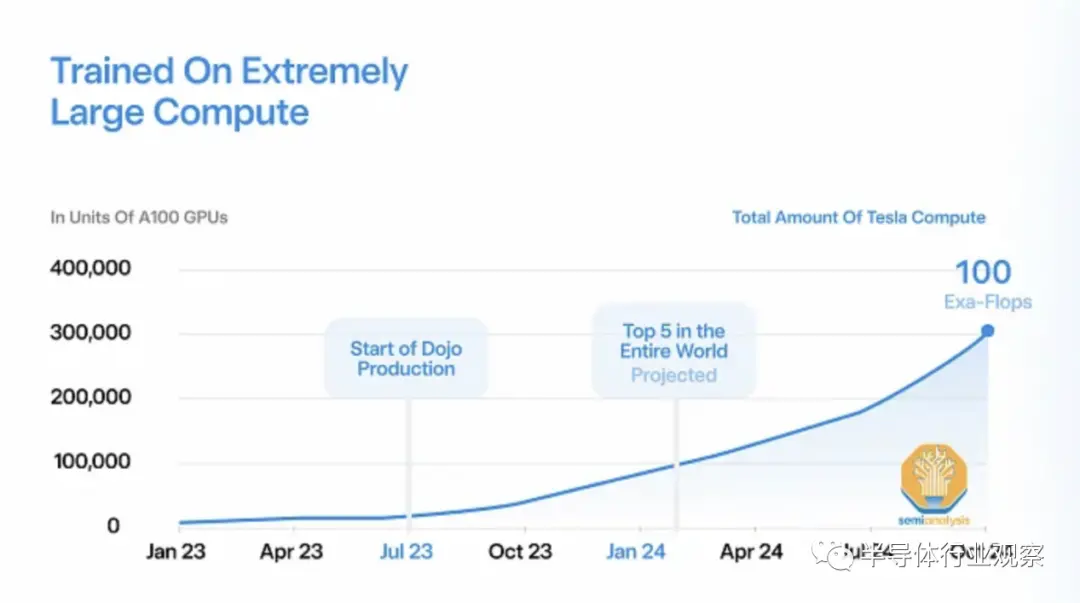
特斯拉目前拥有非常少量的内部人工智能基础设施,只有约 4000 个 V100 和约 16000 个 A100。与世界上其他大型科技公司相比,这个数字非常小,因为 Microsoft 和 Meta 等公司拥有超过 10 万个 GPU,而且他们希望在中短期内将这个数字翻倍。特斯拉人工智能基础设施薄弱的部分原因是其内部 D1 训练芯片多次延迟。
现在故事正在发生变化,而且变化很快。
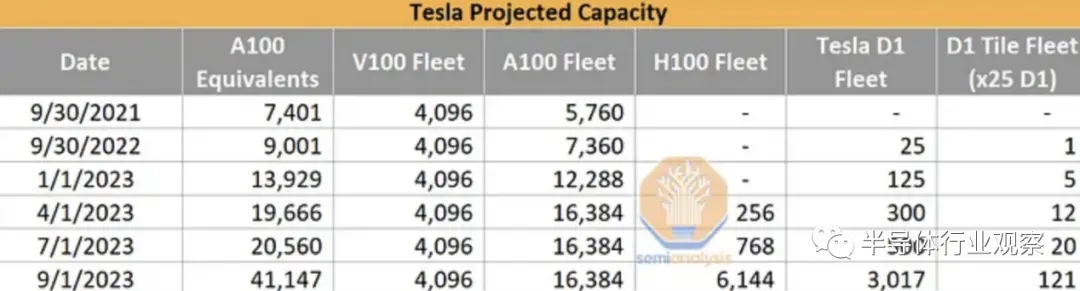
Tesla 正在将其 AI 能力在 1.5 年内大幅提高 10 倍以上。这一部分是为了他们自己的能力,但很大一部分也是为了X.AI。今天,我们希望深入了解 Tesla 的 AI 能力、H100 和 Dojo 的季度产能预估,以及 Tesla 因其模型架构、训练基础设施和包括 HW 4.0 在内的边缘推理而产生的独特需求。
D1训练芯片的故事是一个漫长而艰辛的故事。它面临着从芯片设计到电力传输的问题,但现在特斯拉声称它已经准备好成为众人瞩目的焦点并开始批量生产。回顾一下,特斯拉自 2016 年以来一直在为其 设计内部人工智能芯片,自 2018 年以来一直为数据中心应用设计内部人工智能芯片。
在芯片发布之前,我们披露了他们采用的特殊封装技术。该技术称为 InFO SoW。为了简单起见,可以将其视为晶圆大小的扇出封装。这与 Cerebras 原则上所做的类似,但优点是——允许进行已知良好的芯片测试,这是特斯拉架构中最独特和最有趣的方面,因为这个 InFO-SoW 内置了 25 个芯片,没有直接连接内存。
我们还在 2021 年更详细地讨论了其芯片架构的优缺点。此后最有趣的方面是,特斯拉必须制造另一个位于 PCIe 卡上的芯片来提供内存连接,因为片上内存是不够。
特斯拉本应在 2022 年实现多次产能提升,但由于芯片和系统问题而从未实现。现在已经是 2023 年中期了,它终于开始提高产量了。该架构非常适合特斯拉的独特用例,但值得注意的是,它对于内存带宽严重瓶颈的LLM来说没有用。
特斯拉的用例很独特,因为它必须专注于图像网络。因此,它们的架构差异很大。过去,我们讨论了 学习推荐网络和基于 Transformer 的语言模型如何需要非常不同的架构。图像/视频识别网络还需要不同的计算、片上通信、片上存储器和片外存储器要求的组合。
这些卷积模型在训练期间在 GPU 上的利用率非常低。随着 Nvidia 的下一代产品正在对Transformer(尤其是稀疏 MoE)进行进一步优化,特斯拉对其自己的差异化优化卷积架构的投资应该会取得良好的效果。这些图像网络必须符合特斯拉推理基础设施的限制。
HW 4.0,特斯拉第二代 FSD 芯片
虽然训练芯片是由台积电制造的,但在特斯拉电动 内运行人工智能推理的芯片被称为全自动驾驶(FSD)芯片。特斯拉的车辆型号极其有限,因为特斯拉有一个非常顽固的信念,即他们不需要 的巨大性能来实现完全自动驾驶。此外,特斯拉的成本限制比 Waymo 和 Cruise 严格得多,因为它们实际上出货量很大。与此同时,Alphabet Waymo 和 GM Cruise 正在使用全尺寸 GPU,在开发和早期测试期间,其 成本要高出 10 倍,并且正在寻求为自己的车辆制造更快(也更昂贵)的 SoC。
特斯拉第二代芯片自 2023 年 2 月起在 中发货,该芯片的设计与第一代设计非常相似。第一代基于三星 14nm 工艺,围绕三个四核集群构建,总共 12 个 Arm Cortex-A72 核心,运行频率为 2.2 GHz。然而,在第二代设计中,该公司将 CPU 核心数量增加到五个集群,每集群 4 个核心 (20),总共 20 个 Cortex-A72 核心。
第二代FSD芯片最重要的部分是三个NPU核心。三个内核各自使用 32 MiB SRAM 来存储模型权重和激活(activations)。每个周期,256 字节的激活数据和 128 字节的权重数据从 SRAM 读取到乘法累加单元 (MAC)。MAC 设计为网格,每个 NPU 核心具有 96x96 网格,每个时钟周期总共有 9,216 个 MAC 和 18,432 次操作。每个芯片有 3 个 NPU,运行频率为 2.2 GHz,总计算能力为每秒 121.651 万亿次操作 (TOPS)。
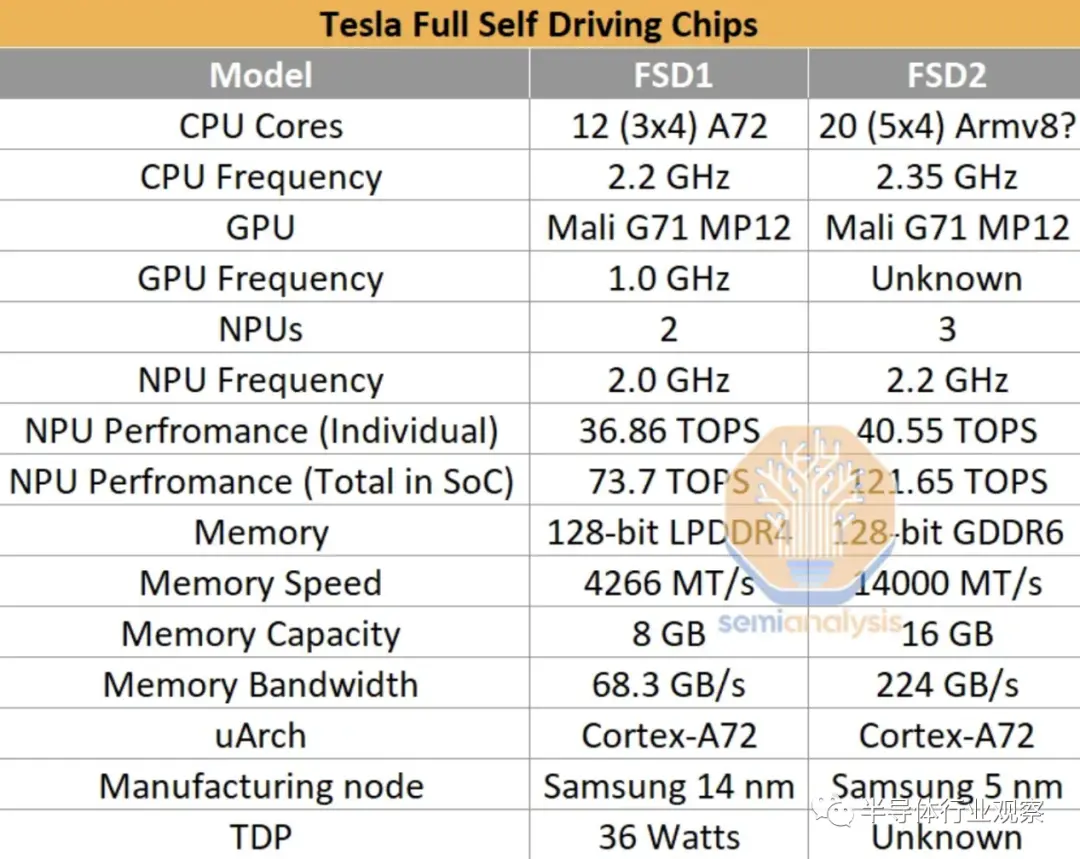
第二代 FSD 拥有 256GB NVMe 存储和 16GB Micron GDDR6(14Gbps),位于 128 位内存总线上,提供 224GB/s 带宽。后者是最值得注意的变化,因为带宽逐代增加了约 3.3 倍。FLOP 与带宽的增加表明 HW3 难以充分利用。每个 HW 4.0 有两个 FSD 芯片。
HW4 板性能的提高是以额外的功耗为代价的。HW4板的空闲功耗大约是HW3的两倍。在高峰期,我们预计它也会更高。HW4的外部电压为 16 伏,电流为 10 安,即使用的功率为 160 瓦。
尽管 HW4 的性能有所提高,但特斯拉希望 HW3 也能实现 FSD,可能是因为他们不想对购买 FSD 的现有 HW3 用户进行改造。
信息娱乐系统采用 AMD GPU/APU。与具有独立子板的上一代相比,它现在也与 FSD 芯片位于同一块板上。

HW4 平台支持 12 个摄像头,其中 1 个用于冗余目的,因此有 11 个摄像头正在使用。在旧的设置中,前置摄像头中心使用三个较低分辨率的 1.2 兆像素摄像头。新平台使用两个更高分辨率的 5 兆像素摄像头。
特斯拉目前不使用激光雷达传感器或其他类型的非摄像头方法。过去,他们确实使用了雷达,但在一代中期被删除了。这大大降低了车辆的制造成本,特斯拉致力于优化车辆,该公司相信纯摄像头传感是自动驾驶车辆的一条可能途径。然而,他们还指出,如果有可行的雷达可用,他们会将其与摄像头系统集成。
在HW4平台上,有一款自行设计的雷达,称为Phoenix。Phoenix 将雷达系统与摄像头系统相结合,旨在利用更多数据打造更安全的车辆。Phoenix 雷达使用76-77 GHz 频谱,峰值有效各向同性辐射功率 (EIPR) 为 4.16 瓦,平均 EIRP 为 177.4 mW。它是一种具有三种传感模式的非脉冲 雷达系统。雷达 PCB 包括用于传感器融合的 Xilinx Zynq XA7Z020 FPGA。
特斯拉 AI 模型差异化
特斯拉的目标是生产基础人工智能模型,为其自动机器人和 提供动力。两者都需要了解周围环境并在周围导航,因此可以将相同类型的人工智能模型应用于两者。为未来的自主平台创建有效的模型需要大量的研究,更具体地说,需要大量的数据。此外,这些模型的推理必须以极低的功耗和低延迟进行。由于硬件限制,这极大地减少了特斯拉可以提供的最大模型尺寸。
在所有公司中,特斯拉拥有最大的可用于训练其 学习神经网络的数据集。道路上的每辆车都使用传感器和图像来捕获数据,并将其乘以道路上特斯拉电动 的数量,得到一个庞大的数据集。特斯拉将其收集数据的部分称为“fleet scale auto labeling”。每辆 Tesla EV 都会拍摄一段 45-60 秒的密集传感器数据记录,包括视频、惯性测量单元 (IMU) 数据、GPS、里程计等,并将其发送到 Tesla 的训练服务器。
Tesla 的模型接受了分割、掩模、 、点匹配和其他任务的训练。通过在道路上拥有数百万辆电动 ,特斯拉拥有大量标记和记录良好的数据源可供选择。这使得能够在公司设施的 Dojo 超级计算机上进行持续训练。
特斯拉对数据的信念与该公司已建立的可用基础设施相矛盾。特斯拉只使用了他们收集的数据的一小部分。由于严格的推理限制,特斯拉因过度训练模型以在给定模型大小内实现最佳精度而闻名。
过度训练小模型会导致全自动驾驶的性能停滞不前,并且无法使用收集到的所有数据。许多公司同样选择进行尽可能大规模的训练,但他们也使用更强大的 推理芯片。例如,Nvidia 计划在 2025 年向 客户提供计算能力超过 2,000 TeraFLOPS 的 DRIVE Thor,这是特斯拉新款 HW4 的 15 倍以上。此外,Nvidia 架构对于其他模型类型更加灵活。
【来源:半导体行业观察】




















