如果 Nvidia 和 AMD 正在摩拳擦掌,想着他们可以将所有 GPU 卖给微软,以支持其在生成人工智能方面的巨大抱负,特别是当涉及到 OpenAI GPT 大语言模型时(该模型是该公司所有未来软件的核心和服务),他们最好再考虑一下。
从生成式人工智能爆发之初我们就一直在说,如果推理需要与训练相同的硬件来运行,那么它就无法产品化。没有人能够负担得起,即使是财力雄厚的超大规模提供商和云构建商。
这就是为什么微软与华盛顿大学的研究人员合作,炮制了一个名为 Chiplet Cloud 的小东西,从理论上讲,它至少看起来在推理方面可以击败 Nvidia“Ampere”A100 GPU(而且对于较小的用户来说),甚至还可以击败包括“Hopper”H100 GPU和运行 Microsoft GPT-3 175B 和 Google PaLM 540B 模型的 Google TPUv4 加速器。
Chiplet Cloud 架构刚刚在一篇基于 Shuaiwen Leon Song 牵头的研究的论文中披露,Shuaiwen Leon Song 是太平洋西北国家实验室的高级科学家和技术主管,也是悉尼大学和悉尼大学未来系统架构研究人员的记忆库。华盛顿大学博士后,于今年 1 月加入微软,担任高级首席科学家,共同管理其Brainwave FPGA 学习团队,并针对 PyTorch 框架运行其DeepSpeed 学习优化,这两者都是微软研究院 AI at Scale 系列的一部分项目。
这些研究并非毫无意义——正如您将看到的,我们真正的意思是——这些项目被 GPT 击败,迫使微软在 Leon Song 加入微软的同时向 OpenAI 投资 100 亿美元。迄今为止,微软已向 OpenAI 提供了 130 亿美元的投资,其中大部分将用于在微软 Azure 云上训练和运行 GPT 模型。
如果我们必须用一句话来概括 Chiplet Cloud 架构(我们必须这样做),那就是:采用晶圆级、大规模并行、充满 SRAM 的矩阵数学引擎,就像 Cerebras Systems 设计的那样,握住它在空中完美水平,让它落在你面前的地板上,然后拾起完美的小矩形并将它们全部缝合在一起形成一个系统。或者更准确地说,不是用 SRAM 做晶圆级矩阵数学单元,而是制作大量单独成本非常低且产量非常高(这也降低了成本)的小单元,然后使用非常快的互连。
这种方法类似于 IBM 对其 BlueGene 系列大规模并行系统(例如安装在劳伦斯利弗莫尔国家实验室的 BlueGene/Q)所做的事情与 IBM 在“Summit”超级计算机中对 GPU 重铁所做的事情之间的区别。BlueGene 与日本 RIKEN 实验室的“K”和“Fugaku”系统非常相似,从长远来看可能一直是正确的方法,只是我们需要针对 AI 训练、HPC 计算以及 AI 推理进行调整的不同处理器。
最近几周,我们一直在讨论构建运行基于 Transformer 的生成 AI 模型的系统的巨大成本,Chiplet Cloud 论文很好地阐述了为什么 Amazon Web Services、Meta Platforms 和 Google 一直在努力寻找制造自己的芯片以使人工智能推理更便宜的方法。
华盛顿大学的迈克尔·泰勒 (Michael Taylor)、胡万·彭 (Huwan Peng)、斯科特·戴维森 (Scott Davidson) 和理查德·施 (Richard Shi) 等研究人员写道:“在 GPU 等商用硬件上提供基于生成式Transformer的大型语言模型,已经遇到了可扩展性障碍。” “GPU 上最先进的 GPT-3 吞吐量为每 A100 18 个token/秒。ChatGPT 以及将大型语言模型集成到各种现有技术(例如网络搜索)中的承诺使人们对大型语言模型的可扩展性和盈利能力产生了疑问。例如,Google 搜索每秒处理超过 99,000 个查询。如果 GPT-3 嵌入到每个查询中,并假设每个查询生成 500 个token,则 Google 需要 340,750 台 Nvidia DGX 服务器(2,726,000 个 A100 GPU)才能跟上。仅这些 GPU 的资本支出就超过 400 亿美元。能源消耗也将是巨大的。假设利用率为 50%,平均功率将超过 1 吉瓦,足以为 750,000 个家庭供电。”
GPU(任何 GPU,而不仅仅是 Nvidia 创建的 GPU)的问题在于,它们是通用设备,因此必须拥有许多不同类型的计算来满足所有用例。你知道这是真的,因为如果不是这样,Nvidia GPU 将只有 Tensor Core 处理器,而没有矢量引擎。即使使用像 Google 的 TPU 这样的设备(本质上只是一个 Tensor Core 处理器),该设备的尺寸和复杂性及其 HBM 内存堆栈也使其交付成本非常昂贵,至少根据微软的比较,提供比 Nvidia A100 GPU 更好的总拥有成本 (TCO)。像这样:
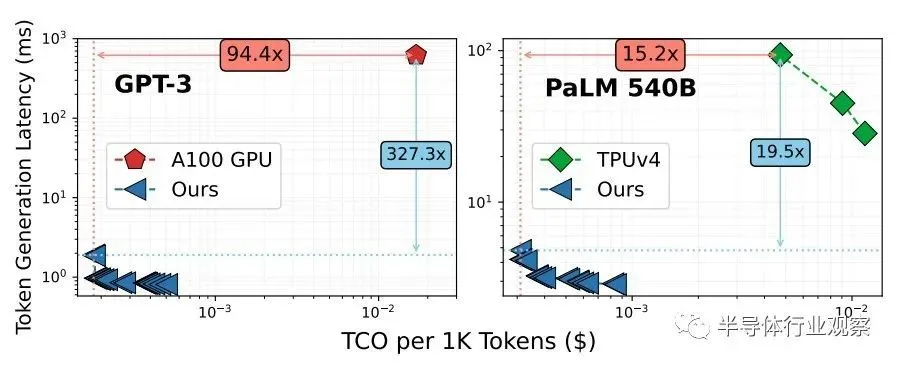
注意:这篇 Chiplet Cloud 论文获得了Lamba GPU Cloud上 A100 容量的定价,当然,TPUv4 定价来自Google Cloud 。
这是上图中所选参考数据点的数据,这很有趣:
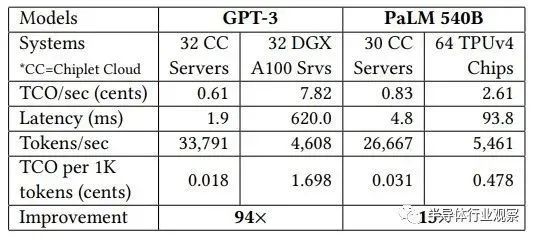
在具有 1750 亿个参数的 GPT-3 模型上,与 Nvidia 的 A100 GPU 相比,模拟的 Chiplet Cloud 设备每处理 1,000 个token的推理成本显著降低了 94.4 倍,token生成延迟显着降低了 327.3 倍。即使 H100 的吞吐量比 A100 高 3.2 倍(将 A100 上的 INT8 吞吐量与 H100 上的 FP8 吞吐量进行比较),我们也没有理由相信即使使用 HBM3 内存,延迟也会有如此大的差异。我们的速度提高了 50%。即使是这样,H100 的市场价格大约是 A100 目前价格的 2 倍。可以肯定的是,H100 会位于上图中 A100 的下方和左侧,但它还有很大的差距需要弥补。
转向具有 HBM 内存的张量核心式矩阵数学引擎在一定程度上有所帮助,如上图右侧采用 TPUv4 计算引擎所示,甚至对于具有 5400 亿个参数的更大的 PaLM 模型也是如此。Microsoft 的理论上的 Chiplet Cloud 显示,运行推理时生成的每 1,000 个token的成本降低了 15.2 倍,延迟降低了 19.5 倍。
在这两种情况下,微软都在优化每个token的低成本,并以合理的延迟来支付费用。显然,如果客户愿意为这些推断支付相应更高的成本,那么通过 Chiplet 云架构,它可以将延迟降低一点。
我们喜欢这张图表,它显示了为什么超大规模企业和云构建者正在考虑用于人工智能推理的定制 ASIC,特别是当大模型需要如此多的计算和内存带宽来进行推理时:
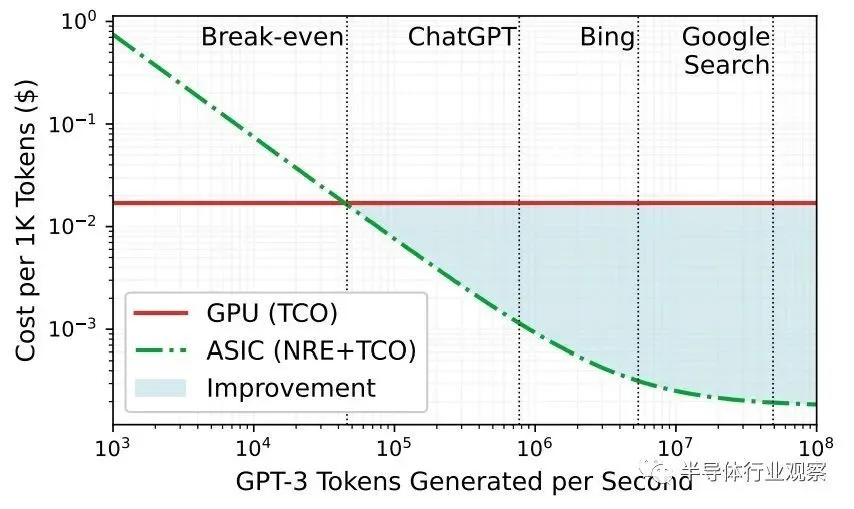
人工智能工作越密集,与使用 GPU 相比,使用 ASIC 的成本改进就越好,顺便说一句,该图表还表明微软知道 Google 搜索比 Bing 搜索密集得多,而且成本也更低。
GPU 和定制 ASIC 之间的收支平衡点约为每秒 46,000 个token。此性能基于在 Lamba GPU 云上运行的 Microsoft 自己的 DeepSpeed-Inference 引擎,每个 GPU 的成本为 1.10 美元/小时,而在模拟 Chiplet 云加速器上运行的 DeepSpeed-Inference 则不同。
在设计 Chiplet Cloud 时,微软和华盛顿大学的研究人员得出了一些结论。
首先,生产芯片的成本是任何计算引擎总体 TCO 的很大一部分。
根据我们的估计,GPU 占现代 HPC/AI 超级计算机 98% 的计算能力,并且可能占 75% 的成本。微软估计,对于采用 7 纳米工艺蚀刻的芯片,制造 LLM 推理加速器的成本约为 3500 万美元,其中包括 CAD 工具、IP 许可、掩模、BGA 封装、服务器设计和人力成本。对于 400 亿美元的潜在投资来说,这是微不足道的。
这意味着如果您想降低成本,就不能使用破坏性的计算引擎。微软等人在论文中表示,对于台积电的7纳米工艺,缺陷密度为0.1个/cm²,750 mm²芯片的单价是150mm²芯片的两倍。
其次,推理既是一个计算问题,也是一个内存带宽问题。
为了说明这一点,不幸的是,使用较旧的 GPT-2 模型和同样较旧的 Nvidia“Volta”V100 GPU,大多数 GPT-2 内核的操作强度较低,这意味着它们毕竟不需要太多的失败,并且受到HBM2的900 GB/秒带宽限制。此外,微软计算出需要 85,000 GB/秒(几乎增加了两个数量级的带宽)才能驱动 V100 GPU 中 112 teraflops 的计算能力来有效运行 GPT-2。
鉴于此,Chiplet 云的秘密正是 Cerebras Systems、GraphCore 和SambaNova Systems 已经弄清楚的:获取模型参数及其关键值中间处理结果,这些结果被回收以加速生成模型,矩阵数学引擎也尽可能接近地存储到 SRAM 中,因为DRAM 和 HBM 之间的差距是如此巨大:
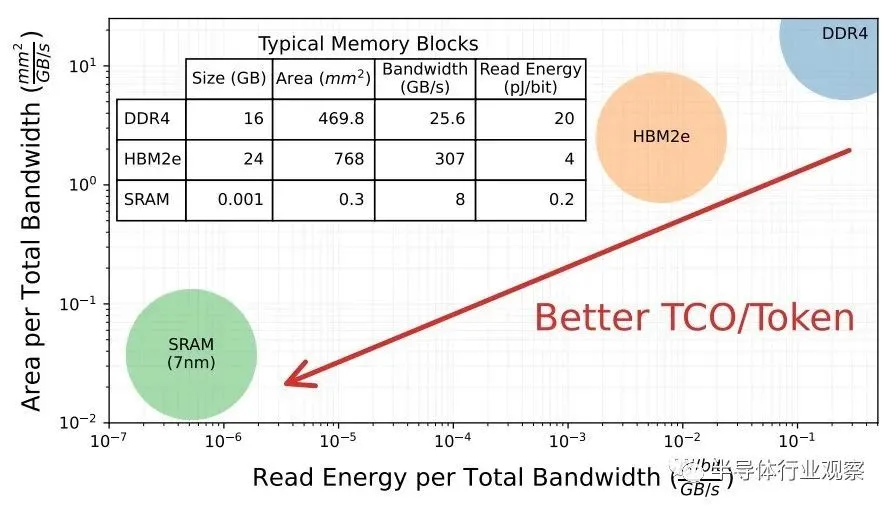
所以 SRAM 在这里似乎是理所当然的。
另一件事是,微软需要一种方法来降低小芯片设计的封装成本,并限制芯片间通信,这会增加推理延迟并降低吞吐量。微软正在使用chiplet作为一个封装,并在板级而不是socket字级进行集成,并使用张量和管道并行映射策略来减少Chiplet云板上的节点间通信。每个chiplet都有足够的SRAM来保存所有计算单元的模型参数和KV缓存。实际上,您拥有一个大规模分布式缓存,然后各个小芯片会在进行自己独特的推理时对其进行咀嚼。
提议的 Chiplet Cloud 如下所示:
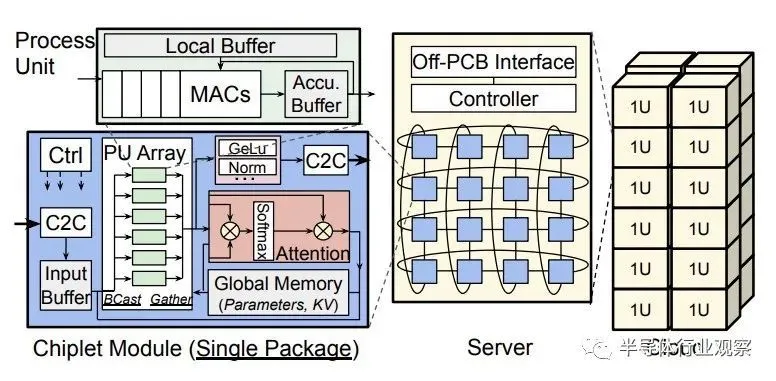
而且它没有硅中介层或有机基板集成,这会增加成本和复杂性,并降低封装级良率,这也是 GPU 和 TPU 等大型、fat、精彩设备的一个问题。该小芯片板使用印刷电路将一堆小芯片连接在 2D 环面中,微软表示,这种电路足够灵活,可以适应设备的不同映射。(这类似于 Meta Platforms 在使用 PCI-Express 交换作为互连的 GPU 加速器系统的电路板上所做的事情。)电路板有一个 FPGA 控制器,每个小芯片都有一个以 25 GB 运行的全双工链路/秒,使用地面参考信号,覆盖范围为 80 毫米。微软表示,其他类型的互连可以根据需要将节点连接在一起。
微软表示,不同的模型需要不同的小芯片计算和内存容量,以及是否针对延迟或 TCO 进行优化。这确实非常有趣:
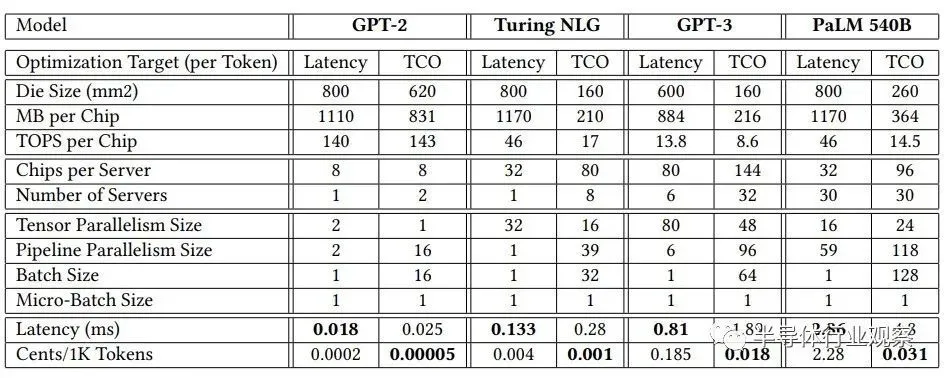
这里的教训是,一种方法不可能适合所有情况。你可以拥有更通用的东西,但你总是付出较低的效率。云构建者需要通用设备,因为他们永远不知道人们会运行什么,除非他们只是打算针对专有软件堆栈销售服务,在这种情况下他们可以疯狂优化并提供最佳性价比并保留一些剩余资金,只有当他们不过度优化(作为利润)时才会发生这种情况。
如果微软向谷歌出售经过优化的Chiplet Cloud以运行5400亿参数的 PaLM ,或者通过定制的 Chiplet Cloud 从 Google Cloud 抢走 TPU 客户,这不是很有趣吗?
我们不确定这个 Chiplet Cloud 有多少仍然是理论,或者它是否正在实施,或者它已经运行了一段时间。不管情况如何,微软在研究上花了一些钱,现在拥有了对抗 Nvidia 和 AMD 的讨价还价筹码。
【来源:半导体行业观察】