2016 年 4 月,Nvidia推出了自主开发的 DGX-1 系统,从组件供应商转变为平台制造商,该系统基于其“Pascal”P100 GPU 加速器和 NVLink 端口的混合立方体网格,将 8 个 GPU 耦合到相当于 NUMA 共享内存集群。
Nvidia 联合创始人兼首席执行官黄仁勋在 GTC 2024 会议的开幕主题演讲中提醒我们,第一款 DGX-1是由 Nvidia 高层亲笔签名的,并由黄仁勋亲自交付给 Sam Altman,他是一位一家名为 OpenAI 的新兴人工智能初创公司的联合创始人,该公司成立于产品交付前的四个月。

在“Volta”V100 GPU 一代中,2017 年 5 月推出的 DGX-1 设计或多或少保持不变,系统的价格标签——Nvidia 曾经给出过价格,还记得吗?– 与 FP32 和 FP64 CUDA 核心上 41.5% 的性能提升相比,提升了 15.5%,在称为张量核心的新事物上,半精度 FP16 数学性能提升了 5.7 倍,从而使性能提升了 79.6%在这种精度下的降压。它还提供用于 AI 推理的 INT8 处理。
然后,人工智能领域的事情变得疯狂,因此 Nvidia 平台架构也必须变得疯狂。
2018 年 5 月,Nvidia 用其完整的 32 GB HBM2 补充来支持 V100 SXM3,而不是 V100 SXM2 所具有的 16 GB,然后抓住了 Nvidia 研究部门一直在搞乱的内存原子开关,并将其商业化为某种东西我们现在称为 NVSwitch。这就是DGX-2平台。

12 个 NVSwitch ASIC 驱动 300 GB/秒内存端口,总双向带宽为 4.8 TB/秒,用于交叉耦合这 16 个 V100 GPU,一组 6 个 PCI-Express 4.0 交换机用于连接两个Intel Xeon SP Platinum 处理器和连接到该 GPU 计算复合体的 8 个 100 Gb/秒 InfiniBand 网络接口。该系统拥有 1.5 TB 主内存和 30 TB 闪存,每个节点的价格高达 399,000 美元,令人惊叹。
但事情是这样的。得益于内存和 NVSwitch 扩展,DGX-2 的性能提高了一倍多,这是人工智能初创公司迫切需要的,这意味着 Nvidia 实际上可以将机器的性价比降低 28%,赚更多的钱。没有人拥有更好的人工智能节点。

随着“Ampere”GPU一代的出现,我们得到了DGX A100系统,该系统于2020年5月在新冠病毒大流行期间推出,Ampere GPU上的NVLink 3.0端口的带宽增加了一倍,达到600 GB/秒,因此六个DGX A100 系统中的 NVSwitch ASIC 必须进行聚合,以匹配相同的 600 GB/秒速度,这意味着将 NVLink 内存集群大小从 16 个减少到 8 个。
DGX A100 有八个 A100 GPU、一对 AMD“Rome”Epyc 7002 处理器、1 TB 主内存、15 TB 闪存和 9 个 Mellanox ConnectX-6 接口(一个用于管理,八个用于 GPU),并带有 PCI- Express 4.0 交换机复合体再次将 CPU 和 NIC 链接到 GPU 复合体。
彼时,Nvidia 刚刚完成以 69 亿美元收购 InfiniBand 和以太网互连制造商 Mellanox Technologies 的交易,并开始使用 InfiniBand 互连将成百上千个 A100 系统粘合在一起创建当时非常大的集群。最初的 SuperPOD A100 拥有 140 个 DGX A100 系统,其中 1,120 个 A100 GPU 和 170 个 HDR InfiniBand 交换机将这些 DGX A100 节点粘合在一起,具有总计 280 TB/秒的聚合双向带宽,并提供略低于 700 petaflops 的聚合 FP16 AI 工作负载的性能。
随着2022 年 3 月推出的“Hopper”H100 GPU 面世,浮点精度减半至 FP8,GPU 变得更强大,最终开始获得更多内存,并且“Grace”CG100 Arm 服务器 CPU 被添加到堆栈并提供 480 GB 的 LPDDR5 内存和 512 GB/秒的带宽,供 GPU 访问超过 600 GB/秒的连贯 NVLink 到 Hopper GPU 复合体中。
以下是 Nvidia DGX H100 系统中使用的 HGX GPU 复合体的样子:

Hopper GPU 上使用的 NVLink 4.0 端口提供 900 GB/秒的带宽,并且 NVSwitch ASIC 必须升级才能在 8 个 H100 GPU 的复合体中提供匹配的带宽。这是通过四个双芯片 NVSwitch 3 ASIC 完成的,您可以在上面的工程渲染图中的 HGX 机箱前面看到它们。
借助 NVSwitch 3 ASIC,Nvidia 将 SHARP 网络内计算算法和电路从 InfiniBand 交换机移植到 NVSwitch 3 ASIC,使其能够在网络中而不是在 DGX 节点 GPU 或 ConnextX 上执行某些集合和归约操作-7 个智能网卡。一些操作——all reduce, all to all, one to many——自然属于网络。
人们仍在部署的 DHX H100 SuperPOD 如下所示:

该机器在 FP8 精度下的额定速度为 1 exaflops,并且还具有 192 teraflops 的 SHAP 网络内处理能力。SuperPOD 复合体中的 256 个 GPU 还拥有 20 TB 的 HBM3 内存。对于那些正在进行实验的人来说,有一种方法可以使用由外部 NVSwitch 3 交换机组成的互连来创建共享内存 GPU 复合体,其中 SuperPOD 中的所有 256 个 GPU 都一致链接。正如我们在此处详细讨论的那样,与 DGX A100 SuperPOD 相比,NVSwitch 互连的 DGX H100 SuperPOD的密集千万亿次性能是 DGX A100 SuperPOD 的 6.4 倍,但重要的是,在 57,600 GB/秒的速度下,其对分带宽是 A100 集群的 9 倍。
尽管这为 Blackwell 系统奠定了基础,但没有人(甚至 Nvidia)投入生产这款完整的基于 NVSwitch 的 DGX H100 SuperPOD。
这最终让我们来到了 Blackwell 平台:

Blackwell 平台从 HGX B100 和 HGX B200 GPU 计算复合体开始,这些计算复合体将部署在 DGX B100 和 DGX B200 系统中,并使用可风冷的 Blackwell GPU 减速变体。
完整的 Blackwell GB100 GPU 被保留用于 GB200 Grace-Blackwell SuperPOD,它将单个 Grace CPU 与一对液冷的 Blackwell GPU 配对,并在称为 GB200 NVL72 的 NVSwitched 系统中使用,顾名思义,该系统有 72 个 Blackwell GPU 通过 NVSwitch 4 互连连接在一起。这种改进的互连可以扩展到 576 个 GPU,理论上比两年前讨论的 NVSwitched DGX H100 SuperPOD 上可用的“横向扩展”多 2.25 倍。
这意味着配备 72 个 Blackwell GPU 的机架是一种新的性能单元,它将取代使用 H100 或 H200 甚至 B100 或 B200 GPU 的 8 个 CPU 节点。并不是说您无法从 OEM 和 ODM 购买这些 DGX 服务器及其克隆,而 OEM 和 ODM 又从 Nvidia 购买 HGX GPU 复合体。
以下是 HGX B100 和 HGX B200 及其 B100 和 B200 GPU 的数据源和速度,这些数据包含在Nvidia Blackwell 架构技术简介中:
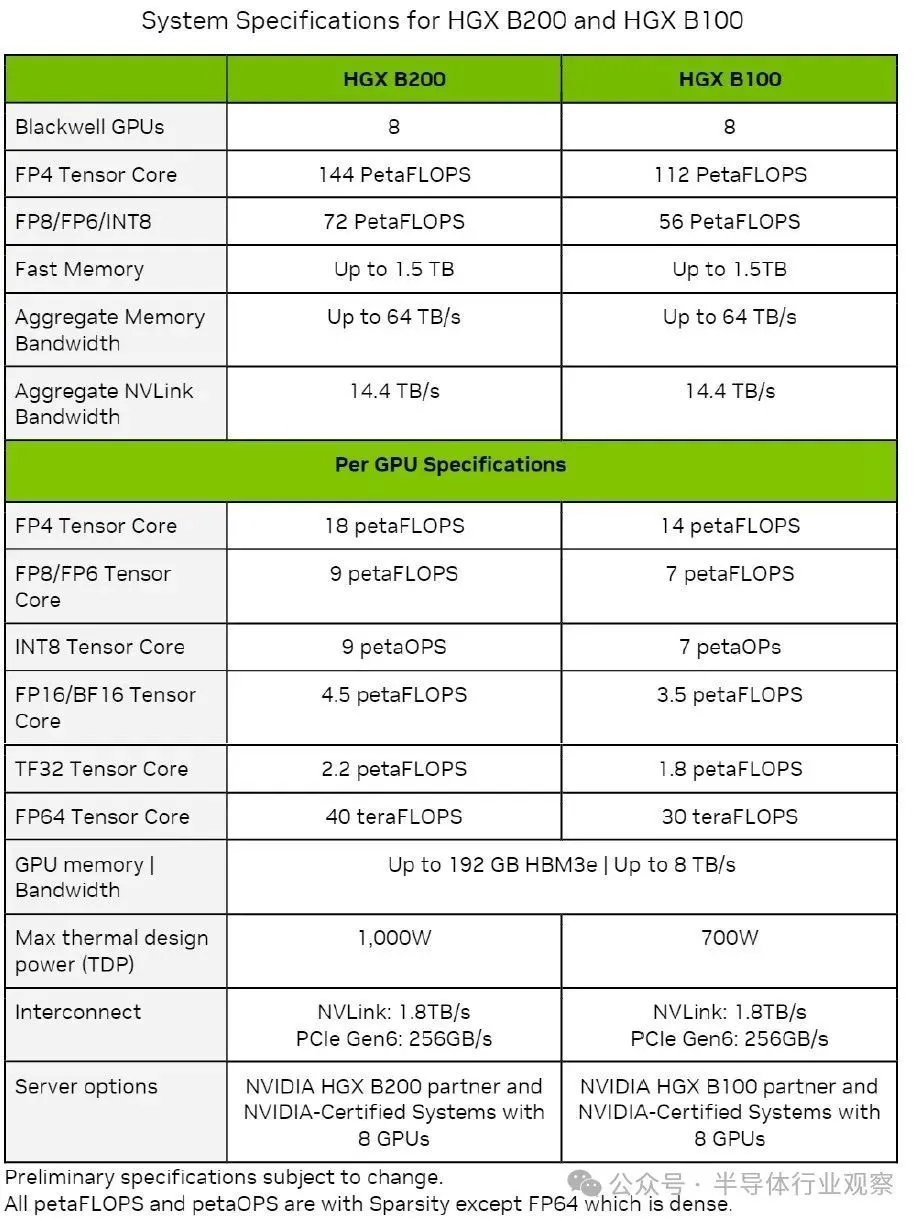
各种精度和数据格式下显示的所有吞吐量均在稀疏性打开的情况下表示,但 FP64 吞吐量除外(FP64 吞吐量在稀疏性关闭的情况下显示)。
我们立即注意到的是,所有数据都显示在张量核心上运行,而不是在 CUDA 核心上运行。这并不意味着 Blackwell 架构中没有 CUDA 核心,但奇怪的是,即使存在,也没有显示出来 - 如果没有 CUDA 核心,那就很有趣了。
另一件突出的事情是内存容量和内存带宽中的所有“up to”警告。如果 B100 和 B200 在今年晚些时候出售时,其 HBM3E 容量低于 192 GB,带宽低于 8 TB/秒,请不要感到惊讶。如果 Nvidia 能够获得制造良率和足够的 HBM3E 内存,这是可能的。但显然 Nvidia 希望在 GB200 系统上销售最高带宽和最高容量的 HBM3E,该系统混合了 Grace CPU 和一对 Blackwell B200 GPU,每个 GPU 在 1,200 瓦热封套中(thermal envelop)运行full-tilt-boogie,并提供完整的 20 Blackwell 两芯片 GPU 复合体固有的 FP4 精度的 petaflops。
HGX B100 GPU 复合体中使用的 B100 与 GHX H100 GPU 复合体中使用的 H100 具有相同的散热性能,因此专为这些 Hopper H100 SXM5 GPU 设计的任何系统都可以使用 Blackwell B100 SXM6 模块,该模块在 FP4 下提供 14 petaflops FP8 时为 7 petaflops。在 FP8 精度下,与 Hopper 芯片相比,每个 Blackwell 芯片的吞吐量提高了 1.8 倍,并且有两个芯片时,FP8 性能提高了 3.6 倍。这强烈表明 Blackwell 芯片上的张量核心比 Hopper 芯片上的张量核心多大约 2 倍。
HGX B200 GPU 复合体中使用的 B200 运行温度提高了 42.9%,每个两芯片插槽可在 FP4 精度下提供 18 petaflops。无论 B200 的运行速度如何,每个 Blackwell 芯片都具有 9 petaflops 的 FP8 精度和稀疏性,这比 H100 芯片高出 2.25 倍,而且有两个芯片,每个插槽的性能提高了 4.5 倍。
制作一个巨大的 GPU
这些 HGX B100 和 HGX B200 系统中的一个新组件是 NVLink 5 端口和 NVLink Switch 4 ASIC,GPU 上的端口可以与它们通信。两者都具有每通道以 100 Gb/秒信令运行的 SerDes 电路,并采用 PAM-4 编码,每个信号携带两位,从而将每通道有效带宽驱动至 200 Gb/秒。通道大规模聚合,可从 B100 和 B200 GPU 复合体上的端口向 NVLink Switch 4(我们有时简称为 NVSwitch 4)ASIC 传输 1.8 TB/秒的双向带宽。该 NVSwitch 4 ASIC 具有 7.2 TB/秒的聚合带宽,这意味着它总共可以驱动四个 1.8 TB/秒的 NVLink 端口。(每个端口有 72 个以 200 Gb/秒的速度运行的通道,令人难以置信。)

该 ASIC 上的 SerDes 驱动 72 个以 200 Gb/秒速度运行的端口,它们与新的 InfiniBand Quantum-X800(以前称为 Quantum-3)中使用的 SerDes 相同,后者具有 115.2 Tb/秒的聚合带宽并可驱动以 800 Gb/秒速度运行的 144 个端口。
以下是 NVLink Switch 4 芯片的放大图:

该芯片拥有 500 亿个晶体管,采用与 Blackwell GPU 相同的台积电 4NP 工艺实现。
新的 NVLink 交换机具有 3.6 teraflops 的 SHARP v4 网络内计算,用于在交换机内部进行集体操作,从而提高 GPU 集群的效率。一些在并行计算中完成的集体操作,特别是计算平均权重并在计算的中间阶段传递它们,最好在网络中执行,该网络位于其连接的节点的本地中心。
有趣的是,NVLink Switch 4 ASIC 可以跨 128 个 GPU 提供机密计算域,并且可以跨最多 576 个 GPU 扩展 NVLink 相干内存结构,后者比 256 个 CPU 理论内存结构规模大 2.25 倍。Nvidia 超大规模和 HPC 总经理 Ian Buck 提醒我们,就像 256 个 GPU 限制只是理论上的限制一样,适用于研究而不是生产,对于 NVLink Switch 3,NVLink Switch 4 的 576 个 GPU 最大限制也适用于研究,而不是生产。
然而,这一次,正如我们现在将要介绍的 GB200 NVL72 系统中所表达的那样,72 个以紧密耦合方式共享 GPU 内存的 GPU 是新的计算单元,就像自 2018 年出现以来的 8 个或 16 个 GPU 一样。DGX 系列系统及其 HGX GPU 复合体和 NVSwitch 互连。曾经的节点现在变成了完整的机架。坦率地说,是时候了。
以下是机架中的组件:

GPU 与 CPU 的 2:1 比例表明,AI 主机不需要如此强大的 Grace,甚至不需要像用于推荐引擎的嵌入那样需要辅助 LPDDR5 内存。Grace 只有一个 600 GB/秒 NVLink 4.0 端口,它被分成两个,使用 300 GB/秒与每个 Blackwell B200 GPU 聊天。这远远超出了 PCI-Express 的能力,事实上,我们要到明年初才会拥有 256 GB/秒的 PCI-Express 6.0 x16 插槽。Nvidia 今年将通过 NVLink 5.0 端口提供的 1.8 TB/秒带宽将持续到 2032 年左右,届时 PCI-Express 9.0 x16 插槽将提供 2 TB/秒的带宽。
以下是 Grace-Blackwell 超级芯片的放大图:

DXG GB200 NVL72 机架系统如下所示:

机架的前部位于左侧,机架的后部位于右侧,带有数英里长的铜电缆。
该机架是新的计算单元,原因很简单:在这些 NVLink 交换机带宽下,机架与组件之间的距离尽可能远,但仍可以通过铜线互连,而不必切换到重定时器、光纤收发器、和光纤电缆。除了机架之外,您还必须进入光学领域,这会增加成本和热量,而且两者都会增加很多。这是我们在系统架构中一次又一次听到的想法。
“这就是让它成为可能的原因,”Nvidia 联合创始人兼首席执行官黄仁勋在对 Blackwell 机架规模设计进行组装和拆卸时解释道。“那是背面,DGX NVLink 主干,130 TB/秒传输到该机箱的背面 – 这超过了互联网的总带宽,因此我们基本上可以在一秒钟内将所有内容发送给每个人。因此,我们有 5,000 根 NVLink 电缆——总共两英里。这是令人惊奇的事情。如果我们必须使用光学器件,我们就必须使用收发器和重定时器,而仅这些收发器和重定时器就需要花费 20,000 瓦(光是收发器就需要 2 千瓦)来驱动 NVLink 主干。我们通过 NVLink Switch 完全免费地完成了这项工作,并且能够节省 20 千瓦的计算电量。整个机架有 120 千瓦,因此 20 千瓦会产生巨大的差异。”
Buck 表示,铜缆和光纤网络链路混合的成本将使 NVLink 交换机结构的成本增加 6 倍。这就是为什么,我们推测,超过 72 个 GPU 的任何东西仍将用于研究,而不是生产,并且这些机架将与 InfiniBand 或以太网互连,而不是 NVLink 交换机,除非您有很多闲钱电力、冷却和光学。
英伟达留下的伏笔
Blackwell 平台高端体现的这种机架规模方法在Nvidia 和 Amazon Web Services 构建的“Ceiba”超级计算机中就已得到体现。该 Ceiba 机器基于 DGX GH200 NVL32,顾名思义,它是基于 NVLink Switch 3 互连的机架规模设计,将 32 个 Grace-Hopper CPU-GPU 超级芯片连接在一起形成一个共享计算复合体。有九个 NVSwitch 系统来互连这些计算引擎,并提供 128 petaflops、20 TB 的总内存(其中 4.5 TB 是 HBM3E,总共 157 TB/秒的聚合内存带宽),所有这些都通过 57.6 TB/秒的聚合 NVLink 链接带宽。
Blackwell GB200 NVL72 将Ceiba的方法提升到了一个完整的 nuthah 水平。
上图显示了 GB200 NVL72 与 DGX H100 相比的倍数。但这并不是真正的比较。
正如黄仁勋在他的主题演讲中所阐述的那样,需要比较的是如何训练来自 OpenAI 的 1.8 万亿参数 GPT-4 Expert LLM。在基于 Hopper H100 GPU 的 SuperPOD 集群上,在节点外部使用 InfiniBand,在节点内部使用 NVLink 3,需要 8,000 个 GPU 花费 90 天和 15 兆瓦的电量才能完成训练运行。要在相同的 90 天内在 GB200 NVL72 上运行相同的训练,只需要 2,000 个 GPU 和 4 兆瓦。如果使用 6,000 个 Blackwell B200 GPU 完成此任务,则需要 30 天和 12 兆瓦。
Buck 向我们解释说,这实际上并不是一个计算问题,而是一个 I/O 和计算问题。通过这些Expert modules的混合,可以实现更多层的并行性以及这些层之间和内部的通信。数据并行性——将数据集分成块并将部分计算分派给每个 GPU——这是 HPC 和早期人工智能计算的标志。然后是张量并行性(跨多个张量核心打破给定的计算矩阵)和管道并行性(将神经网络处理层分派到各个 GPU 以并行处理它们以加快速度)。现在我们有了模型并行性,因为我们有一组专家进行训练和推理,这样我们就可以看到哪一个最擅长给出这种答案。
Buck 表示,为了找出在 GB200 NVL72 集群上运行 GPT-4 训练的正确并行配置,Nvidia 进行了 2,600 多次实验,以找出创建硬件的正确方法,并对模型进行切分和切片,使其运行为尽可能高效。以下是其中一些实验,绘制如下:
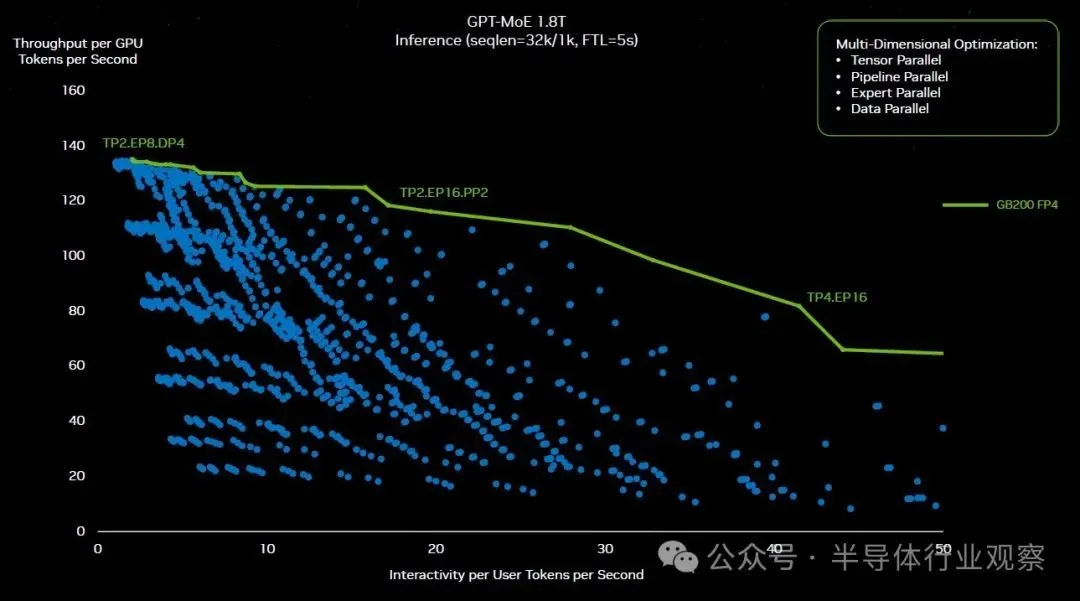
“所有这些蓝点都来自于软件的重新分区,”黄在他的主题演讲中解释道。“一些优化解决方案必须弄清楚是否使用张量并行、专家并行、管道并行或数据并行,并将这个巨大的模型分布在所有这些不同的 GPU 上,以获得您所需的持续性能。如果没有 Nvidia GPU 的可编程性,这个探索空间是不可能的。所以我们可以,因为 CUDA,因为我们拥有如此丰富的生态系统,我们可以探索这个宇宙并找到绿色屋顶线。”
现在,这是 Hopper 和 Blackwell 屋顶线在 1.8 万亿参数下在 GPT-4 MOE 上工作的样子,只是为了好玩,中间有一条紫色的理论 Blackwell 线,它显示了 Blackwell 如果只是将 NVLink Switch 3 和 400 Gb/秒 InfiniBand 混合在一个集群中,因为 Hopper 系统已完成并坚持 FP8 精度,并且没有转移到新的 Transformer Engine 和 FP4 处理进行推理。一种简单的芯片升级,但不是系统升级:
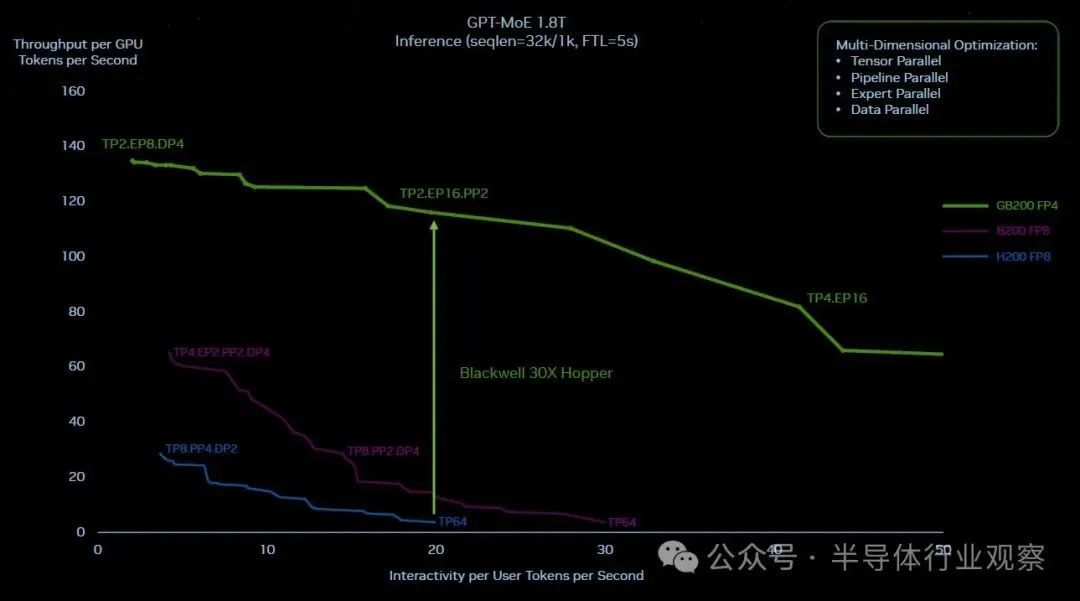
显然,仅仅对进行Hopper 粗略升级以制作Blackwell并不是答案。正如 Nvidia 声称的那样,所有将推理性能提高 30 倍并将推理功耗降低 25 倍的举措都是正确的举措。
这里有很多同时发生的效果。在仅由 16 个 Hopper 级 GPU(两个与 InfiniBand 互连的 HGX 板)组成的集群上运行此 GPT-4 MOE 模型,由于跨并行级别的集体操作,机器大约 60% 的实际时间用于通信只有 40% 仅用于计算。更快、更宽的 NVLink Switch 互连允许使用更多的计算。
通过跨 72 个 GPU 的 NVLink Switch 互连,这些 GPU 可以以惊人的速度相互通信,并且在必要时它们可以同时相互通信并快速完成通信。不仅如此,GB200节点中每个节点有两个GPU,而不是GH200节点每个节点只有一个GPU。每个 GPU 的 HBM3E 内存大约是原来的两倍,带宽也几乎是原来的两倍。在液冷 GB200 NVL72 配置中,这两个 Blackwell 插槽具有 40 petaflops 的 FP4 oomph,而一个 Hopper 插槽具有 4 petaflops 的 FP8 oomph。
网络显然与计算一样重要。
顺便说一句,其中 8 个 GB200 72NVL 机架现在包含一个 SuperPOD,您可以将它们与 800 Gb/秒 InfiniBand 或以太网互连,或者进行实验并链接半排机架中的所有 576 个 GPU,以创建更大的共享记忆系统。后者的网络费用可能几乎与计算费用一样大。但是,有了 576 个 GPU 内存和计算域,这可能是值得的......毕竟,几年后,该行将成为新节点。根据当前趋势,大约两年后。不久之后,数据中心将成为新节点。
【来源:半导体行业观察】