AI 带来对算力需求指数级增长的同时,也带来了日益庞大的智算系统,人工巡检难以做到全面覆盖和及时发现问题。经验判断也可能因为智算系统的复杂性和特殊性而出现偏差。例如,传统的备份和恢复方法可能无法满足实时性要求,一旦出现故障,数据丢失的风险将大大增加。
新的运维挑战,不仅是工作体量的增加,还有资源管理与协调优化、安全性与稳定性、故障处理等多方面的变化。
因此,智算中心运维也将越来越依赖智能化系统,更自动化地完成性能监控预警、故障诊断和自动恢复等,并且能够提供一定的辅助决策分析。同时,智算中心运维的灵活性和可扩展性也将有赖于微服务架构、容器化技术和池化技术等,以促进应用与服务的快速部署、更新和维护。
以故障诊断为例,大模型等集群计算任务的涌现,故障定位在分布式系统中不可避免地面对定位时间长、复杂程度高等问题。传统的运维方式可能需要花费大量时间才能找到问题的根源,如果导致业务中断时间过长,会给企业带来巨大的损失。如此一来,快速处理关键业务故障,也对于系统观测的精准度提出更高的要求。
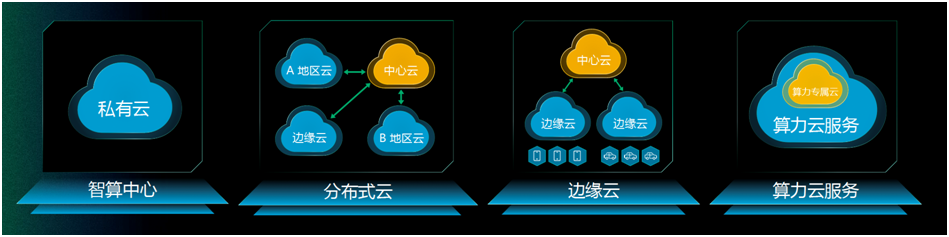
青云科技致力于解决智算中心建设、运维管理与运营中的挑战与痛点,已经落地了近 30 个区域智算中心,深知高效运维是智算中心稳定运行与运营的重要保障。
通过灵活的 AI 算力交付方式,青云智算中心解决方案将多个地区的算力中心统一管理、运维和运营,极大提高了资源利用效率的同时,节省了大量的配置和安装时间,提高了部署的效率和准确性,使系统更容易适应业务变化,有效减轻了运维人员的工作负担,提升运维效率。
通过节点监控、任务监控、容器组监控、高速网络监控和 GPU 监控等功能,青云科技提供从硬件故障处理到资源使用情况的全方位监控,及时发现并解决潜在问题,同时拥有可视化的自定义告警配置,支持邮件、企微、Webhook 等多种通知渠道,确保用户随时掌握 AI 基础设施的运行状态。
为应对技术复杂、时间压力及人员技能要求等挑战,青云科技进一步推出故障监控与自愈系统。系统拥有 1000+ 故障特征库,能够秒级发现故障并分钟级自愈。
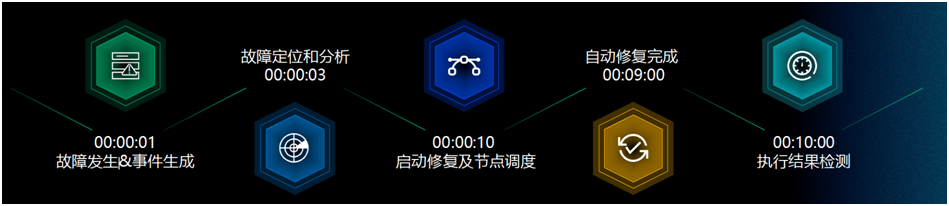
一旦平台检测到故障,发出告警后,系统会自动启动任务检测和调度禁止机制,防止新任务在故障机器上运行。对于正在运行的任务,系统会检查其健康状态,并根据情况决定是否继续在当前机器上运行或转移到其他正常机器上。在资源充足的情况下,系统会预留部分机器作为备份,以便在故障发生时迅速接管任务,保证任务连续性,从而提高工作效率。
青云科技将持续 AI 算力产品与服务迭代,为智算中心的稳定运营、高效管理与运维保驾护航,共同满足持续增长的智算资源与服务需求,携手拥抱更美好的 AI 未来。















