2 月 17 日消息,微软 OmniParser 是一款基于纯视觉的 GUI 智能体解析和识别屏幕上可交互图标的 AI 工具,此前搭配 GPT-4V 可显著增强识别能力。
2 月 12 日,微软在官网发布了 OmniParser 最新版本 V2.0,可将 OpenAI(4o / o1 / o3-mini)、DeepSeek(R1)、Qwen(2.5VL)和 Anthropic(Sonnet)等模型,变成可以操控计算机的 AI 智能体。

与 V1 版本相比,OmniParser V2 使用了更大规模的交互元素检测数据和图标功能标题数据进行了训练,在检测较小的可交互 UI 元素时准确率更高、推理速度更快,延迟降低了 60%。
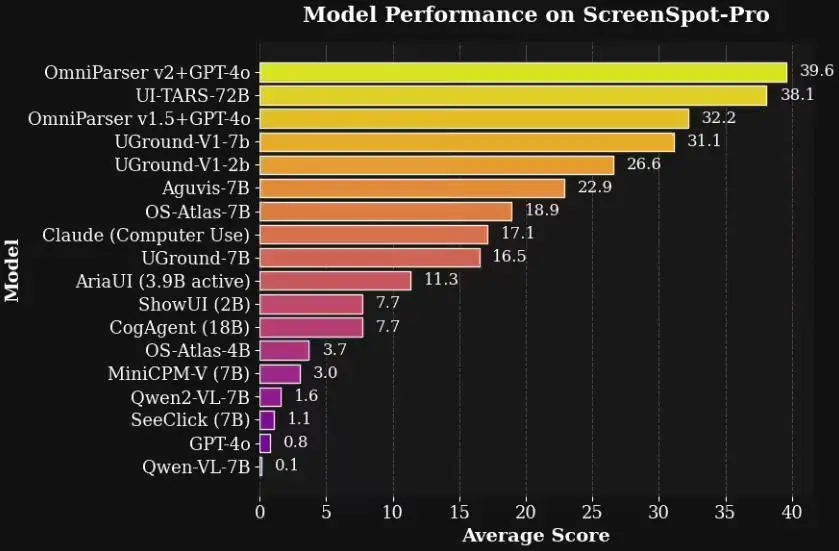
在高分辨率 Agent 基准测试 ScreenSpot Pro 中,V2+GPT-4o 的准确率达到了 39.6%,而 GPT-4o 原始准确率只有 0.8%。
为了能够更快地实验不同的智能体设置,微软还开源了 OmniTool,这是一个集成了智能体所需一系列基本工具的 Docker 化 Windows 系统,涵盖屏幕理解、定位、动作规划和执行等功能,也是将大模型变成智能体的关键工具。
IT之家附开源地址:
https://github.com/microsoft/OmniParser
【来源:IT之家】