4月12日消息,字节跳动于4月8日发布博文,其Seed研究团队推出VAPO强化学习训练框架,目标提升大型语言模型在复杂、冗长任务中的推理能力。
现有挑战
在大型语言模型(LLM)的强化学习(RL)训练中,价值导向方法(Value-based reinforcement learning methods)因能精确追溯每个动作对后续回报的影响,展现出巨大潜力。然而,应用于长链式推理(CoT)任务时,价值模型面临三大挑战。
首先,价值模型初始化会引入偏差;其次,传统方法难以适应复杂任务中的序列长度差异;最后,验证任务中奖励信号稀疏,优化过程面临探索与利用的权衡,这些问题限制了价值导向方法的实际效果。
VAPO 简介
字节跳动最新推出的VAPO框架全称为Value Augmented Proximal Policy Optimizationd(增强价值的近端政策优化),基于PPO框架,通过三项创新技术应对上述挑战。
首先,VAPO模型构建了细致的价值训练框架,增强模型对复杂任务的理解。其次,引入长度自适应广义优势估计(GAE)机制,能根据响应长度动态调整参数,优化长短序列的训练效果。最后,VAPO整合了多项先前研究技术,形成协同增效的系统。
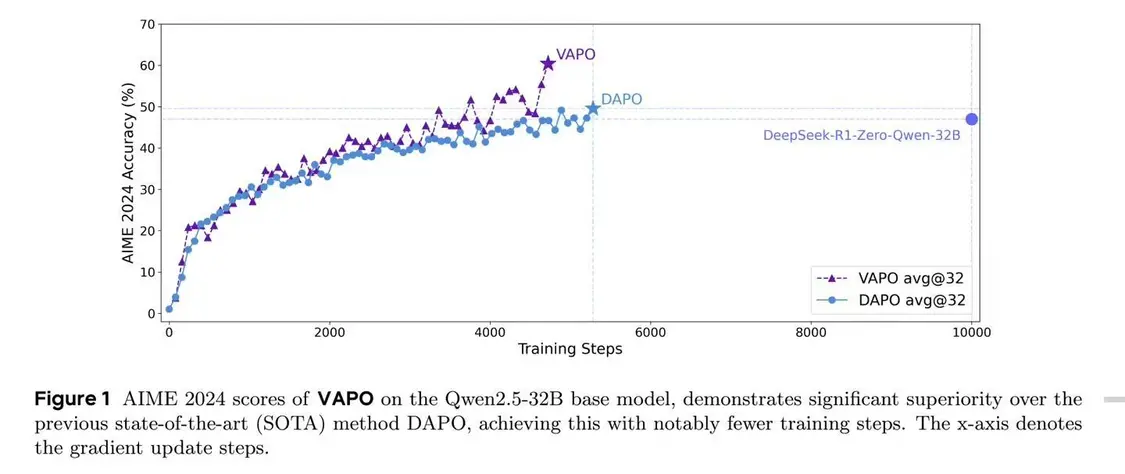
在不依赖特定监督微调(SFT)数据的情况下,Qwen2.5-32B模型通过VAPO优化后,在 AIME24 基准测试中将得分从5分提升至60.4分,超越DeepSeek R1的47分,超过此前 SOTA 方式 DAPO(50分)10分,仅用60%的更新步骤即达成业界领先。
相较于传统Proximal Policy Optimization(PPO)算法,VAPO改进了数学推理能力,训练曲线更为平滑,优化过程更稳定。
测试显示,归因于其价值模型提供的细粒度信号,VAPO在长序列任务中表现出色,得分增长更快。尽管后期训练熵值降低可能限制探索,VAPO通过平衡设计确保了稳定性和可重复性。
VAPO的成功源于其综合优化设计。消融研究验证了七项技术的有效性:价值预训练防止崩溃,解耦GAE支持长回答优化,自适应GAE平衡短长回答,剪裁策略鼓励探索,词级损失增加长回答权重,正例语言模型损失提升6分,分组采样贡献5分。
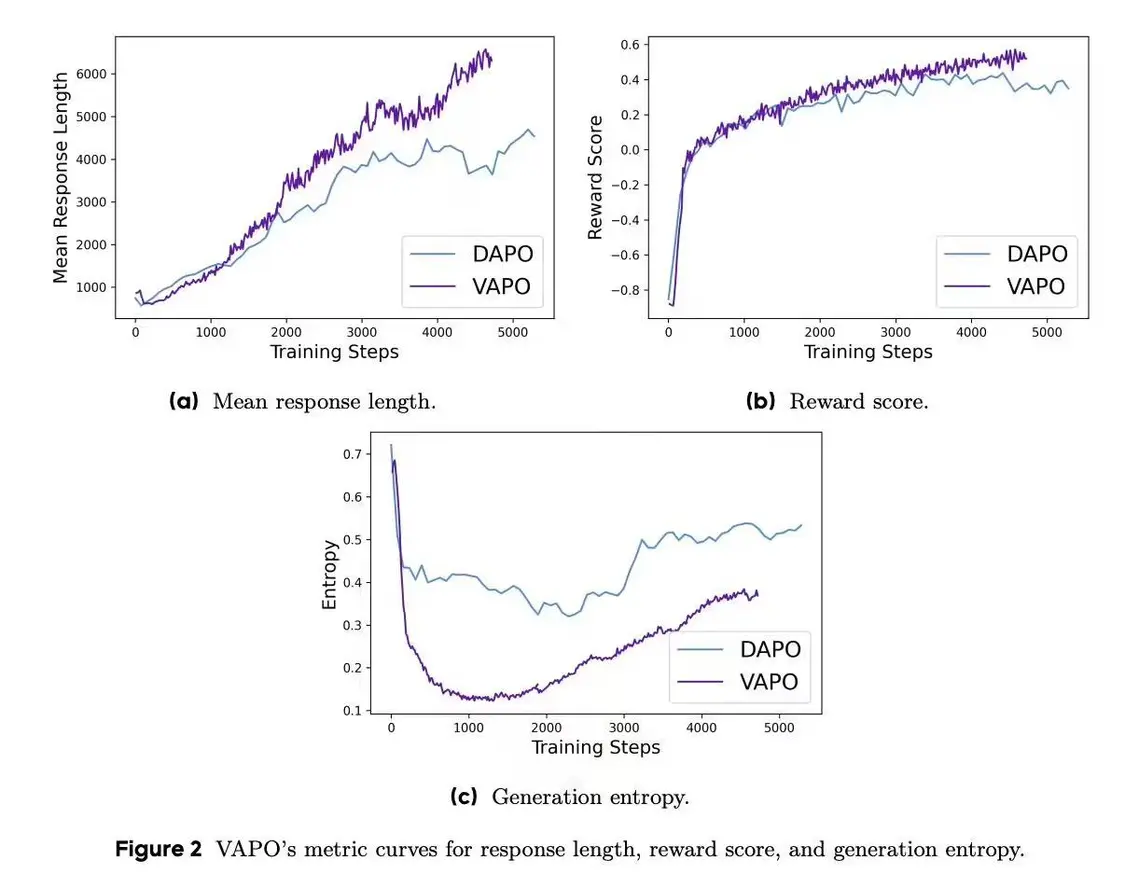
这些改进使VAPO在探索与利用间找到最佳平衡,显著优于无价值导向的GRPO和DAPO方法。VAPO不仅提升了数学推理能力,还为LLM在复杂推理任务中的应用提供了新方向。
【来源:IT之家】




















