声网 AI 模型评测平台(对话式)2.0 版本近日正式上线,评测维度迎来重磅升级:测试区域新增至10个,覆盖全球各大洲核心城市;模型可选择数量提升3倍;ASR 模型新增多种语言下的错词率评估;TTS 模型新增中英文场景下的词错误率和字母数字性能对比,同时 TTS 功能支持用户自主输入中英文文本内容,一键生成语音效果。
AI 模型评测平台(对话式)凭借提供 ASR+LLM+TTS 主流供应商的延迟数据横向测评,上线以来受到众多开发者的青睐,此次2.0版本新增多项对话式 AI 体验质量评估维度,不仅为开发者在级联大模型选型时提供了更丰富的可视化参考,也让选型决策更精准、更高效。
测试区域覆盖全球10大核心城市 模型数量提升3倍
AI 模型评测平台(对话式)测试区域由原先的中国大陆-上海,新增了新加坡、日本、洛杉矶、法兰克福等9个全球主流城市,且ASR+LLM+TTS 的模型数量提升了3倍,例如 LLM 大模型新增了Step 2 mini、Llama 3.3 70B、GPT 4.1 mini、Gemini 2.0 Flash、Claude Haiku 3.5等国内外主流的大模型,ASR 与 TTS 也新增了 OpenAI、Microsoft Azure、Cartesia 等知名 AI企业旗下的主流模型。
通过测试区域以及模型选择数量的提升,可以精准匹配不同地区开发者的需求与关注焦点,为全球用户提供更丰富的选择空间。
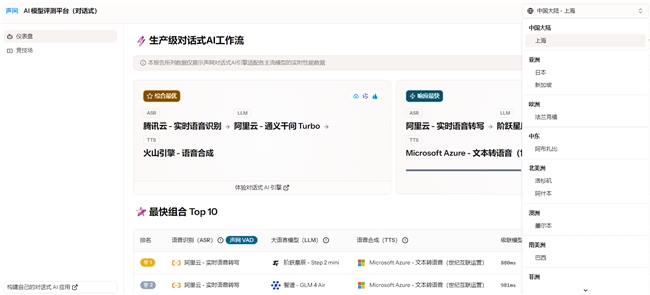
图:AI模型评测平台右上角可选择测试区域
ASR 新增9种语言错词率评估 TTS 准确性实现可量化
ASR 模型的横向评测维度在末字延迟(TTLW)的基础上新增了词错误率(WER)的评估,并支持在中文、英语、日语、法语等9种语言下的测试对比,全面反映模型在不同语言识别场景的精度。
AI 模型评测平台的 ASR 错词率检测基于交互式测试方法(Turn Detect),以300ms的超时判定模拟用户的感知阈值,旨在评估最佳对话体验下 ASR 模型的实际可用性。在测试中我们也发现,在对话式场景下,ASR 模型需要在实时性和准确性之间做出更精细的权衡,一些在非对话式场景下准确率最高的模型(如OpenAI系列)并不一定是对话式场景的最佳选择。
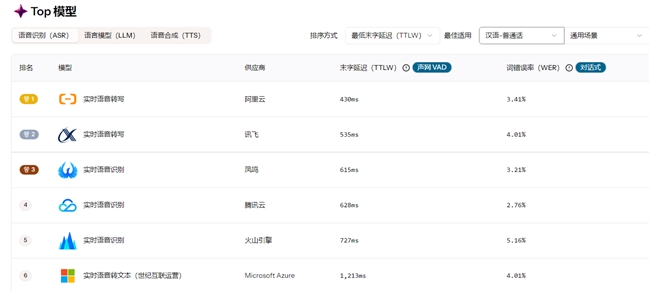
图:ASR模型评测新增词错误率对比
同时,TTS 模型了新增中英文场景下的词错误率(WER)和字母数字性能(AP) 指标,词错误率体现了TTS 模型在通用场景下的表现,数值越低,TTS 准确性越高。字母数字性能通过统计 TTS 模块对包含多音字、数字、缩写、公式、标点符号的复杂文本中每个字符的正确生成比例,全面衡量其对多类型特殊字符的精准处理能力,数值越高,TTS 准确性越高。
首字节延迟、词错误率,字母数字性能三类指标的评测让 TTS 语音合成的准确性进一步被量化,技术对比更具参考价值。
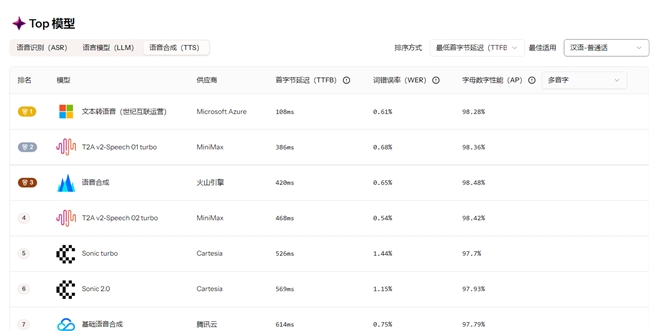
图:TTS 模型评测新增字母数字性能对比
“竞技场”支持自主输入文本并一键生成语音
AI 模型评测平台的“竞技场”提供开发者自主选择不同的 ASR、LLM、TTS 模型进行延迟性能的对比,在新增词错误率与字母数字性能两项指标后,“竞技场”内的模型评测结果也新增了这两项指标的对比。
同时在 TTS 的对比中,在原先支持语音合成测试语句试听的基础上,新增了支持用户自主输入文本内容,一键生成语音合成效果的对比,并支持中英文。通过个性化试用场景,帮助用户快速验证技术与实际需求的匹配度,让选型决策更高效。
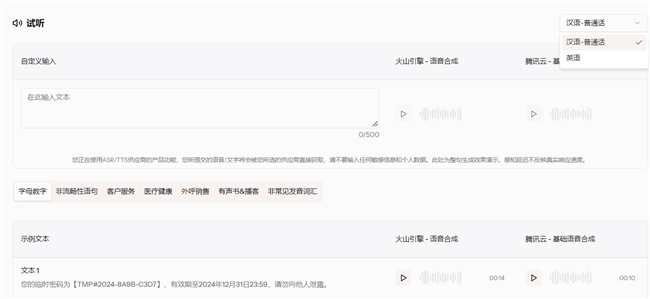
目前,新版 AI 模型评测平台已正式上线声网官网,如您想进一步体验,可找到声网官网的对话式AI页面进行体验。















