最近 AI 圈子里,大家聊得最多的,可能不是又出了什么惊天动地的新模型,反而是另一种更普遍的情绪:焦虑。
算力焦虑。
大家都在谈论规模。更大的模型,更强的算力集群。这当然没错,力大砖飞,简单有效。但当所有人都挤在同一条路上时,这条路必然会变得拥堵且昂贵。算力成本,已经从一个技术问题,变成了一个战略问题,甚至是生存问题。
今年初 DeepSeek R1 的消息,让全世界兴奋了一下。它证明了通过复杂的训练范式,比如强化学习,无需陷入参数无限堆砌的误区,就能显著提升模型的推理和工具使用能力。
这说明通往山顶的路不止一条。
这件事,也引发了另一个更深层的问题:如果说 DeepSeek 的路径,是用更聪明的“训练方法”去优化一个既定的“模型”,那么,有没有可能,在更早的阶段,在模型架构本身、在数据处理的源头,就已经存在着一条被忽视的“效率之路”?
这是一条更底层、更枯燥、也更难走的路。它不追逐时髦的概念,而是沉潜到技术最根本的环节,去抠每一个环节的能效比。愿意走这条路的公司寥寥无几,毕竟,它的成果少了些噱头感。
但你顺着这条线索梳理不难发现,仍有部分团队在该领域持续深耕。九章云极 DataCanvas 就是其中尤为突出的一家。
近期,九章云极频繁地在 ACL、EMNLP 这些顶会上发表多篇专业论文,连起来看会发现一个非常清晰的技术哲学。他们似乎在系统性地回答一个问题:在通往高性能模型的路上,有多少“成本”是可以被技术和工程的智慧所节省下来的?
发动机的设计:参数效率
首先,九章云极把目光对准了模型这个“发动机”本身。
现在很多团队做模型,有点像在造肌肉车,简单粗暴地堆大排量。九章云极的一篇关于 YuLan-Mini 的研究,则是在尝试造一台 F1 赛车的引擎。参数量不大,只有 24 亿,但目标是逼近 70 亿参数模型的性能。

这背后是对模型训练稳定性的极致追求。小模型想发挥出超越自身规模的性能,训练过程就必须非常激进,比如使用很高的学习率。而这又极易导致训练崩溃。为了解决这个矛盾,他们用了一套组合拳,从参数初始化方法,到一种叫“重参数化”的技术来吸收梯度变化,本质上是在给这台高转速引擎设计更可靠的冷却和润滑系统。
更有意思的是他们对“燃料”的选择,也就是数据。他们不只是把海量数据投喂进去,而是设计了一套精细的数据流水线。其中一个亮点是,在预训练阶段就引入了“形式化数学”这种高度逻辑化的数据。
这说明,他们认为模型的强大,不应该只来自于对海量文本的统计学模仿,还应该来自于对底层逻辑规则的理解。这就像教一个孩子,你不能只让他背唐诗,还得让他做数学题。前者塑造语感,后者锻炼逻辑。
最终,这个 24 亿参数的模型,用 48 张卡就完成了训练。这个数字本身,就体现了一种效率观。但这不仅仅是为了在预训练阶段省钱。这更是在为下一步,也就是智能体时代的真正核心技术——强化学习,打下一个坚实的基础。
强化学习,是训练模型做出复杂决策、与环境交互的核心方法,但它的训练过程出了名的昂贵和“数据饥渴”。如果你的基础模型本身就是一个“油老虎”,参数臃肿、逻辑不清,那么后续的强化学习训练成本将会是天文数字。
九章云极的这个思路,本质上是在优化“智能体的总拥有成本”。通过算法创新,先打造一个参数效率和逻辑能力都极高的基础模型,相当于给未来的智能体一个“节能”的内核。这使得后续的强化学习过程,可以用更少的算力、在更短的时间内,达到更好的训练效果。这是一种深思熟虑的、着眼于最终工程化落地的技术选择,其重要性在智能体训练中愈发凸显。
推理的成本:从“蛮力”到“巧劲”
发动机造好了,怎么让它在路上跑得更省油?如果说基础模型是智能体的“躯体”,那么如何决策和行动,就是智能体的“灵魂”。这正是强化学习技术的核心用武之地。
智能体的行动,本质上是一个与现实世界不断交互、学习、优化的循环。它需要感知环境、做出判断、执行动作,然后根据结果反馈来调整下一步策略。九章云极在这方面发表的系列论文,清晰地展现了他们如何通过强化学习的创新,去打磨智能体与现实交互的每一个环节,让这个过程从“蛮力试错”走向“四两拨千斤”。
第一步:让智能体“看清”世界,而不是“看花”
智能体与现实交互,第一步是信息输入。在数字世界里,这个“现实”往往就是海量的文档和数据。当上下文窗口动辄达到上百万 token,智能体面临的首要问题就是“信息过载”。
九章云极《CAFE》这篇论文,解决的就是这个问题。它没有采用复杂的外部处理模块,而是深入模型内部,利用 Transformer 架构中那些天然擅长信息检索的“注意力头”,作为智能体内部的“侦察兵”。通过一个“粗筛”和“精读”的两步策略,帮助智能体在信息海洋中快速定位关键证据。这本质上,是用一种巧妙的机制设计,优化了强化学习中至关重要的“感知”(Perception)环节。一个能快速看清问题本质的智能体,才有可能做出正确的决策,从而极大提升后续强化学习的训练效率。

第二步:让智能体“学会”思考,而不只是“被动”学习
看清世界之后,智能体需要决策。这是强化学习的主战场。国际上,像 DeepMind 等顶尖机构,在强化学习上的研究往往气势磅礴,通过海量算力进行大规模的模拟和探索,让智能体在数百万次试错中“涌现”出智能。这毫无疑问是前沿的,但成本也是巨大的。
九章云极的系列研究,则展现了另一种可比肩国际水平的、更侧重工程化和效率的思路。
他们的《R1-Searcher++》论文,就是这种思路的集中体现。它同样使用强化学习,但核心目标是训练智能体形成一种“判断力”和“记忆力”。“判断力”指的是,智能体要自己学会,什么时候可以依赖自己的内部知识,什么时候必须向外部环境(如搜索引擎)求助。这解决了智能体与现实交互中的一个核心成本问题:减少不必要的动作。

而论文名字里的“++”,则指向了更深层的“记忆机制”。智能体通过与环境交互学到的新知识,会被吸收、内化,成为自己知识体系的一部分。这使得智能体能够持续成长,而不是在同一个地方反复跌倒。
这种对智能体“决策成本”和“知识积累”的精细优化,是典型的工程化思维。它与国际上更偏向“暴力美学”的强化学习探索形成了鲜明对比和互补。后者在探索智能的上限,而九章云极则着力降低智能的门槛,让训练一个聪明的、能与现实高效交互的智能体,变得更加可行。
更有意思的是,在《SimpleDeepSearcher》这篇论文里,他们甚至展示了对强化学习本身的“反思”。他们发现,对于某些特定任务,与其用复杂的强化学习去“训练”,不如用高质量的“教学数据”去“教会”模型。这种在不同技术路径间灵活选择、永远追求最高投入产出比的务实态度,恰恰是强化学习从实验室走向产业应用最需要的能力。
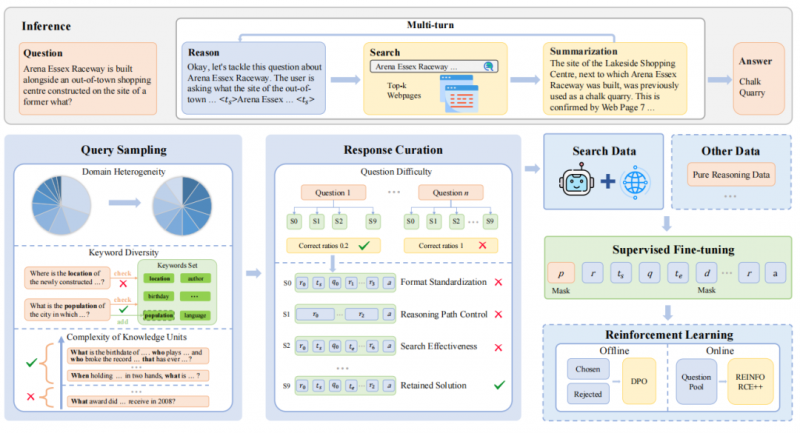
总而言之,这一系列成果,清晰地勾勒出一条通往“智能体时代”的技术路线:以强化学习为核心,通过创新的算法和务实的工程化能力,让智能体在与现实世界的交互中,变得更高效、更聪明、也更“便宜”。
看不见的地基:平台与工程
这些关于算法和数据效率的研究,都建立在一个更核心的底层支撑之上:一个稳定、高效的AI基础设施平台。在讨论强化学习时,这一基础的重要性怎么强调都不为过。
纸上谈兵容易,但要把这些精细的优化策略,在真实的训练任务中跑起来,不出问题,本身就是巨大的工程挑战。强化学习的训练过程,比传统的监督学习要脆弱得多。它充满了随机性,实验结果难以复现,训练过程随时可能因为一个微小的参数变化而崩溃。
若缺少一个工业级的、为强化学习这种“精细活” 优化的平台,绝大多数关于智能体的设想,终究只能停留在论文层面,难以落地。
值得注意的是,前述相关研究的实验,均是在九章云极自家的智算云平台上完成的。而这个平台并没有完全封闭。比如,他们向清华大学的“AI for Science”黑客松提供开源平台,学生和科研人员可以在该平台上进行各类算力实践。这可以看作是一种对自身平台能力的“公开路演”和“压力测试”。
而支撑这一切的,是更早期的布局。他们在2025年4月授权的一个关于“分布式强化学习训练方法”的专利,以及随后发布的全球首个实现工程化落地的强化学习云平台,这些都不是孤立的事件。它们共同指向了一个事实:九章云极在很早之前,就已着手系统性地解决“如何让强化学习变得可靠和可用”这个核心工程问题。
从底层的智算调度,到上层的训练框架,再到为高校场景优化的“Aladdin”这类算力服务,他们构建的是一整套让强化学习,特别是智能体训练,能够顺利进行的“生命支持系统”。
模型会迭代,算法会更新,但一个稳定、高效、低成本,并且积累了大量复杂任务工程经验的基础设施平台,才是最难被快速复制的东西。它就像一个F1车队的后勤维修体系和风洞实验室,决定了你的赛车能稳定跑完全程,并且不断迭代优化,而不是在某个弯道突然爆缸。
回到最初的问题。在一个被“规模”定义一切的时代,为什么要去走一条看起来更慢、更难的“效率之路”?
现在看来,这可能不是一个快慢的问题,而是一个选择问题。是选择把自己的天花板,建立在自己能买到多少张 GPU 上,还是建立在自己对技术理解的 上。
“普惠算力”,这个词已经被说得太多了。
但剥开各种宏大的叙事,它的内核可能很简单:就是通过技术和工程上的不懈努力,持续降低 AI 的使用成本,无论是训练成本,还是推理成本。
这背后,没有太多激动人心的故事可讲。它不是关于一次性发布一个“王炸”模型,而是关于在无数个不起眼的环节里,一点一滴地优化、改进、提升效率。
在 AI 行业陷入规模内卷,九章云极通过系统性技术优化与工程创新,证明了一条聚焦效率的可行路径——从模型设计、数据处理到基础设施,全方位降低 AI 门槛,为智能体时代提供更可持续的技术基础。这一路径虽不炫目,却能从根本上解决行业痛点,推动 AI 技术的普惠化与产业化。
这或许不是一个最能吸引眼球的故事,但它可能是一个更坚实,也更可持续的故事。















